
Mohammad Hosein Gheysarieh
Author
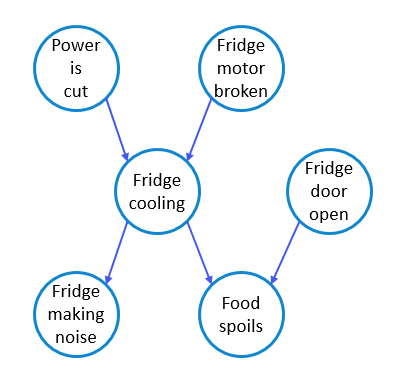
Imagine this scenario. You want to know if the food in your fridge is going to spoil. You can hear your fridge humming. Does that change the probability of the food spoiling? What if you see that the fridge door is open? Are these evidences even related to the food spoiling? In this lecture note, we want to introduce a probabilistic model to study this kind of problems.
So, what is a probabilistic model? A model is a simplification of the real world; it describes how portions of the world work. Since models are simplifications, they do not contain all the details and may not account for every variable or interaction between variables. As George E. P. Box, a British statistician once said: "All models are wrong; but some are useful."
We use probabilistic models to reason about unknown variables, given evidences. This can be done in three ways:
Two variables are independent if:
$$\forall x, y : P(x, y)=P(x)P(y)$$If two variables are independent, their joint distribution is the product of their distributions. This can also be shown in another way:
$$\forall x, y : P(x\mid y)=P(x)$$We show independency as:
$$X\perp Y$$Note that real life joint distributions are at best close to independent. Independence is a modelling assumption. We'll get back to assumptions later.
Unconditional (absolute) independence is very rare to come by, because the variables in a problem are usually all correlated. Conditional independence is our most basic and robust form of knowledge about uncertain environments.
$X$ is conditionally independent of $Y$ given $Z$,
$$X\perp Y\mid Z$$if and only if
$$\forall x,y,z:P(x,y\mid z)=P(x\mid z)P(y\mid z)$$or equivalently, if and only if
$$\forall x,y,z:P(x\mid z,y)=P(x\mid z)$$We all know the basic form of chain rule:
$$P(X_1,X_2,...,X_n)=P(X_1)P(X_2\mid X_1)P(X_3\mid X_1,X_2)...$$Imagine we want $P(X, Y, Z)$. Using the chain rule, we can write:
But if we know that $Z$ and $Y$ are independent, we can instead write:
These independencies can be derived from bayes' nets. This will come in handy when we want to infer probabilities from bayes nets.
There are two problems with using full joint distribution tables as our probabilistic models: 1. Unless there are only a few variables, the joint is WAY too big to represent explicitly (With $2^n$ rows from $n$ variables). 2. Hard to learn (estimate) anything empirically about more than a few variables at a time. For example, to find the probability of two variables being true at the same time, we would have to calculate a sum over $\frac{2^n}{4}$ rows which can be an unreasonably big calculation.
Bayes nets is a technique for describing complex joint distributions or models using simple and local distributions.
Bayesian net's graphical notation consists of a graph, and one conditional probability table for each dependency.
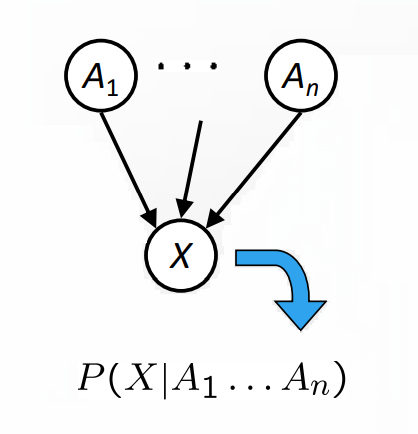
In this picture there are a set of nodes, one per variable $X$. And we have a directed and acyclic graph. Each node of this graph shows a conditional distribution.
In BNs, joint distribution is obtained by the product of local conditional distributions. So, to find the probability of a full assignment, multiply all relevant conditional probabilities.
$$P(x_1, x_2,... , x_n)=\prod_{i=1}^{n}P(x_i|Parents(x_i))$$
In the following part, we will prove this method is correct.
First note the chain rule applied to each distribution:
$$P(x_1, x_2,... , x_n)=\prod_{i=1}^{n}P(x_i|x_1,x_2,...,x_{i-1})$$
Now with respect to conditional independence, we can claim that:
$$P(x_i|x_1,x_2,...,x_{i-1})= P(x_i|Parents(X_i))$$
Which is true because xi is conditionally independent of other nodes, given its parents. In other words, by knowing the values of all the parents, the other nodes no longer give us new information, and it does not matter to us whether we know them or not.
So, we can conclude that:
$$P(x_1, x_2,... , x_n)=\prod_{i=1}^{n}P(x_i|Parents(x_i))$$
Note that not every BN can produce every distribution, but the BN topology determines what conditional independence can be produced.
See the following examples of BN distribution.
a. coin flips
In this case, a coin is tossed n times, the probability of a head or tail being equal in each toss. If these actions are independent of each other, then the graph is as shown in the image.
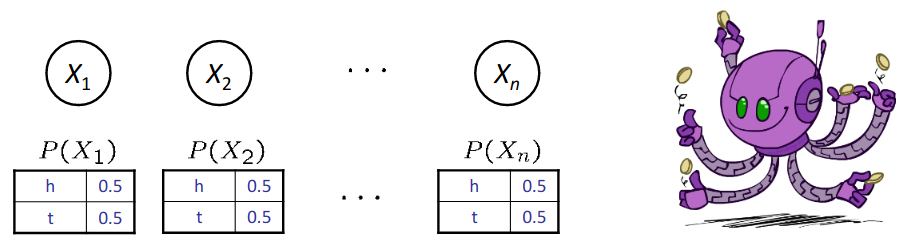
For example $P(H, T, T, H) = P(H)P(T)P(T)P(H)$
Note that only distributions whose variables are absolutely independent can be represented by a Bayes’ net with no arcs.
b. traffic
In this example, R stands for rain and T stands for traffic. It is also assumed that rain causes traffic.
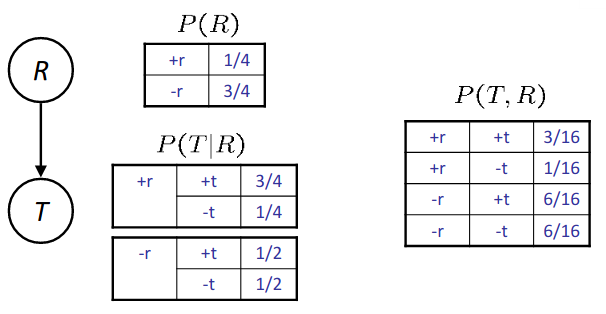
For example $P(+r, -t) = P(+r)P(-t|+r)$
c. alarm network
In this case, it is assumed that the house alarm goes off by an earthquake or burglary. John and Mary may also call us if the alarm is ringing.
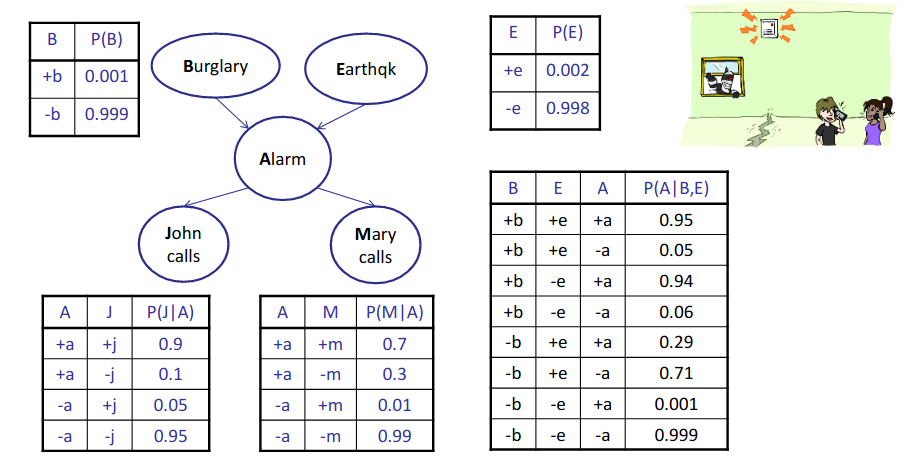
For example $P(+b,-e,+a,-j,-m)=P(+b)P(-e)P(+a|+b,-e)P(-j|+a)P(-m|+a)$
If in a Bayes' net the arrows represent the real causes, it can be better investigated and the probabilities are easier to find. The network also becomes simpler. Because the number of parents is fewer.
Sometimes arrows do not represent causal relationships. Or even in some networks, none of the arrows have a causal relationship. For example, when some important variables are not available in the network. In such cases, the arrows show correlation and not causation.
Therefore, we do not need to know the exact causal structure between the variables.
The CPT size of a node depends on it's domain and parents. if a node has $k$ parents and each of which has $m$ different value, the CPT size is equal to $m^{k+1}$.
Therefore, in a Bayes' net with $N$ Boolean variables, if each node has a maximum of $k$ parents, the size of the whole net is of the order of $O(N\times 2^{k+1})$. Whereas if we want to store their joint distribution, it is the size of $2^N$.
So, we conclude that if we use this method, it usually requires less memory. It is also easier and faster to use local CPTs.
In previous sections we used conditional dependencies. But in a big graph, finding dependencies with algebraic methods is so difficult and complex. In this section we present an algorithm called D-separation to find different conditional dependencies.
In this method, first we check conditional dependency for triples (3 nodes that are connected) and specify several rules to find whether the last and first variables are dependent or not. Then we use these rules to find conditional dependencies in general cases on bigger graph. In another words, in big graphs we do some processing on each triple in the path between the two desired nodes to find if they are independent.
In the following section, we will examine three different situations for triples:
The first configuration is “casual chain”.
In this configuration, middle node transmits the effect of the previous node to the next one.
Example:
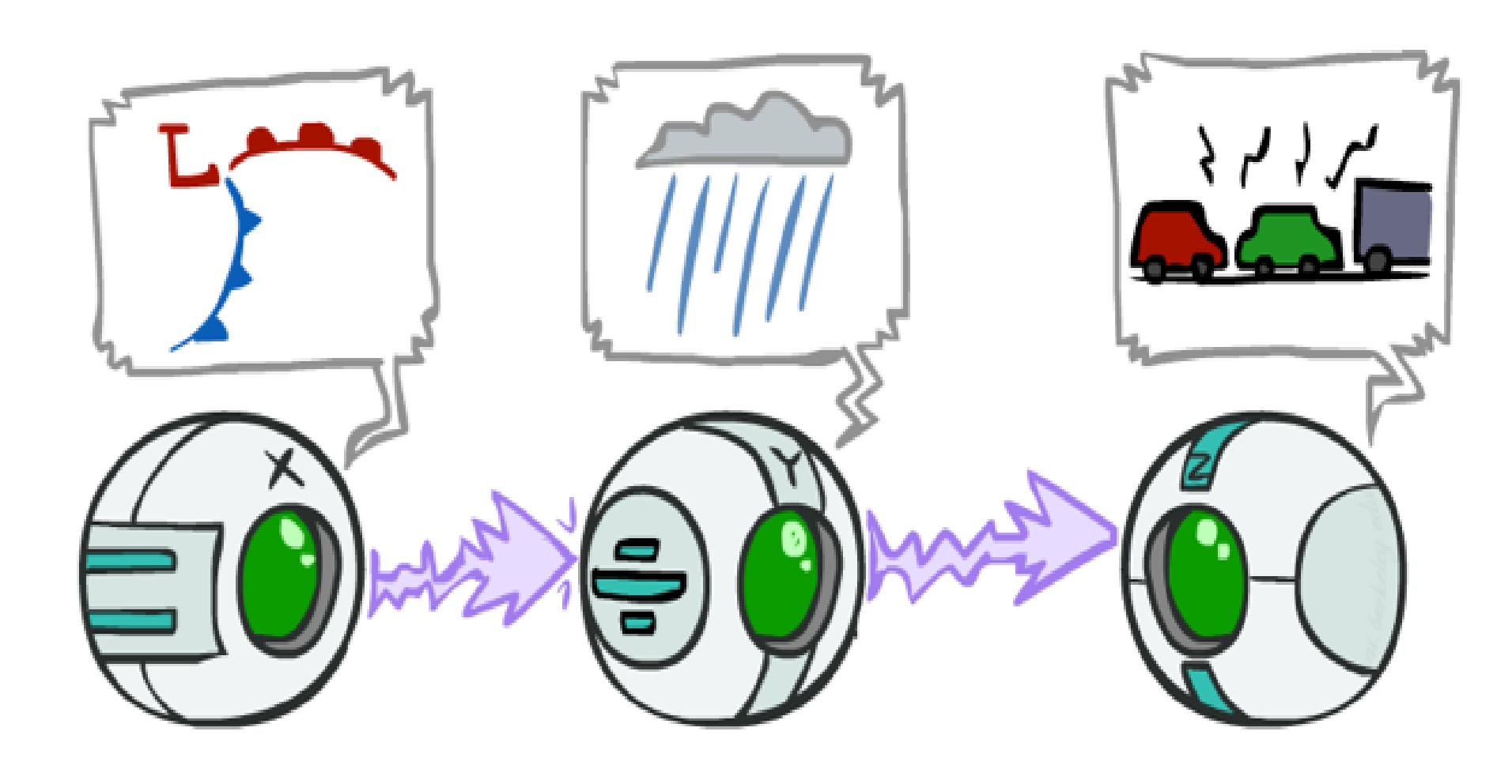 - $$P(X, Y, Z) = P(X) P(Y|X) P(Z|Y)$$
- $$P(X, Y, Z) = P(X) P(Y|X) P(Z|Y)$$
In this BN, low pressure causes rain and rain causes traffic. in another word rain transmits the effect of low pressure to traffic.
is $X$ is guaranteed to be independent of $Z$?
the answer is NO. To prove this claim, it is enough to give an example that $X$ and $Z$ are dependent. suppose that $X$ is random, and probability of low pressure $(P(+x))$ and high pressure $(P(-x))$ are equal to 0.5. $P(+x)=P(-x)=0.5$
rainfall is completely dependent on low pressure and if low pressure occurs, rainfall is definite. and if high pressure occurs, rainfall is impossible.
$$P(+y|-x)=0 , P(+y|+x)=1$$
Also, traffic is completely dependent on rainfall. if it rains, traffic will occur and otherwise there isn’t any traffic.
$$P(+z|+x)=1 , P(-z|-x)=1$$
now we should compare $P(Z)$ and $P(Z|X)$ to find dependency. for example low pressure and traffic occurred. $(X=+x and Z=+z)$ we know $P(+z|+x)=1$ but $P(+z)=0.5$
As a result, the two variables are not independent.
is $X$ is guaranteed to be independent of $Z$ given $Y$?
the answer is YES. to prove this claim, we use algebraic operations. we should show equality of $P(Z|Y)$ and $P(Z|Y,X)$.
$$P(Z|X,Y)=\frac{P(X,Y,Z)}{P(X,Y)}=\frac{P(X)P(Y|X)P(Z|Y)}{P(X)P(Y|X)}=P(Z|Y)$$
we conclude that with condition on $Y$, $X$ and $Z$ are independent.
So, in triple casual case, if middle node is observed, end nodes are independent. because the effect of $X$ to $Z$ is not direct, if the value of $Y$ is known, changes in value of $X$ causes no effect on Z’ value. in other word if we know value of $Y$, value of $X$ doesn't give any additional information about $Z$.
So, evidence along the chain “blocks” the influence.
second configuration is “common cause”:
in this configuration one variable effect on another two variables. but child nodes are not related directly.
Example:
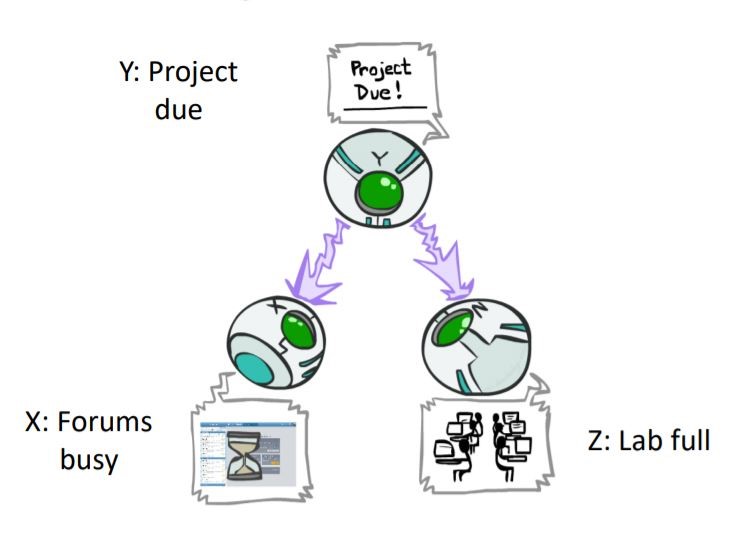 - $$P(X, Y, Z) = P(Y) P(X|Y) P(Z|Y)$$
- $$P(X, Y, Z) = P(Y) P(X|Y) P(Z|Y)$$
in this BN, project due causes lab full and forums busy.
is $X$ is guaranteed to be independent of $Z$?
the answer is NO. it is enough to give an example set of CPTs that $X$ and $Z$ are dependent. suppose that $Y$ is random, and the probability of being close to project deadline $(P(+y))$ and otherwise $(P(-y))$ are equal to 0.5. $P(+y)=P(-y)=0.5$
laboratory fullness is completely dependent on project deadline and if deadline is near, laboratory is full. and if project deadline is not near, laboratory is not full.
$P(+z|+y)=1 , P(+z|-y)=0$
Also, forums are related to project deadline. if deadline is near, forums get busy.
$P(+x|+y)=1 , P(+x|-y)=0$
now we should compare $P(Z)$ and $P(Z|X)$ to find dependency. for example, lab is full and forums are busy. $(X=+x and Z=+z)$ we know $P(+z|+x)=1$ but $P(+z)=0.5$. because value of $Z$ and $X$ are exactly equal to the value of $Y$.
As a result, the two child variables in common cause triples are not independent in general case.
is $X$ is guaranteed to be independent of $Z$ given $Y$?
the answer is Yes. to prove this claim, we use algebraic operations. we should show equality of $P(Z|Y)$ and $P(Z|X,Y)$.
$$P(Z|X,Y)=\frac{P(X,Y,Z)}{P(X,Y)}=\frac{P(X)P(Y|X)P(Z|Y)}{P(X)P(Y|X)}=P(Z|Y)$$
we conclude that with condition on $Y$, $X$ and $Z$ are independent.
So, in triple common cause, if parent node is observed, child nodes are independent. because the effect of $X$ to $Z$ is not direct, if value of $Y$ is known, changes in value of $X$ causes no effect on $Z$’ value. in other word if we know value of $Y$, value of $X$ doesn't give any additional information about $Z$.
So, observing the cause blocks influence between effects.
the last configuration is "common effect" and is sometimes called V-Structure.
in this configuration, one variable is affected by another two variables.
Example:
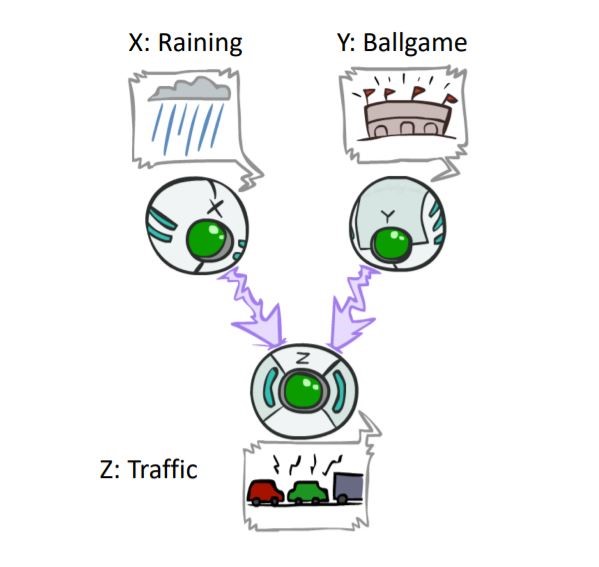 - $$P(X, Y, Z) = P(X) P(Y) P(Z|X, Y)$$
- $$P(X, Y, Z) = P(X) P(Y) P(Z|X, Y)$$
in following BN, both ballgame and raining cause traffic.
is $X$ is guaranteed to be independent of $Y$?
the answer, unlike previous versions, is Yes. ballgame and rain do not get effect from each other or a common cause. to prove this claim, use algebraic operation again:
$$P(X,Y)=\sum_{z}^{}P(X,Y,z)=\sum_{z}^{}P(X)P(Y)P(z|X,Y)=P(X)P(Y)\sum_{z}^{}P(z|X,Y)=P(X)P(Y)$$
So we show $P(X,Y) = P(X)P(Y)$ and conclude $X$ and $Y$ are independent.
is $X$ is guaranteed to be independent of $Y$ given $Z$?
the answer is NO. with an example we describe the situation. consider $X$ and $Y$ have random values and probability of occurrence of each one is 0.5. $(P(+x)=P(+y)=0.5)$ and traffic will occur when ballgame or raining occurs.
$P(+z|+x,+y)=P(+z|+x,-y)=P(+z|-x,+y)=1 , P(+z|-x,-y)=0$
From the problem description, We can conclude that $P(+x|+z,-y)=1$ and $P(+x|-y)=0.5$. So, $P(X|Z,Y)$ is not equal to $P(X|Y)$.
So, with the observation of $Z$, $X$ and $Y$ are not independent. this means Observing an effect, activating influence between possible causes.
In the same way, it can be shown that if one of $Z$ descendants is also observed, the independence of $X$ and $Y$ is no longer guaranteed. To prove this from the previous issue, it is enough to add the condition that the occurrence or non-occurrence of each of $Z$ descendants is always the same as its parent.
Now, we want to use these three cases to check conditional dependency in any arbitrary graph. generally, the problem is checking dependency between two random variables in a BN in which some (or any) variables are observed. for this goal, we break the graph into triples which we learned above, and do some checking on them. In the following, these steps are described.
in the first step, we should shade evidence nodes, nodes that are observed in the problem. then looking for undirected paths between determined random variables. the first idea is that if two nodes are connected by a path that is blocked by a shaded node, two random variables are independent. But there are drawbacks to this rule. when we have several paths between two RVs or there is a V-structure triple that its bottom node is shaded, our method is wrong. So, we describe the next step to correct these problems.
Question: are $X$ and $Y$ conditionally independent given evidence variables $Z$?
Yes, if $X$ and $Y$ “d-separated” by $Z$.
to describe the "d-separated" concept, we first need to understand the concept of active/inactive path.
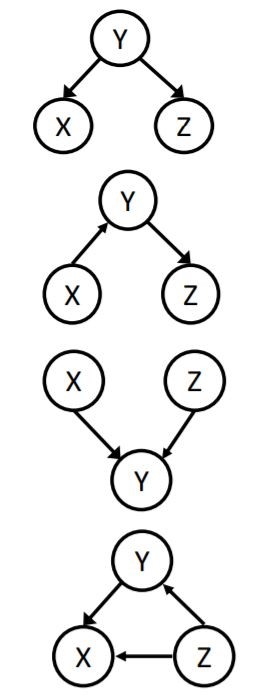
a path is active if each triple of it is active. a triple is active if:
Now we consider all undirected paths from $X$ to $Y$ after shading evidence variables, if none of these paths aren’t active paths, we can say $X$ and $Y$ are d-separated by $Z$.
in the figure below, examples of active and inactive triples are shown.
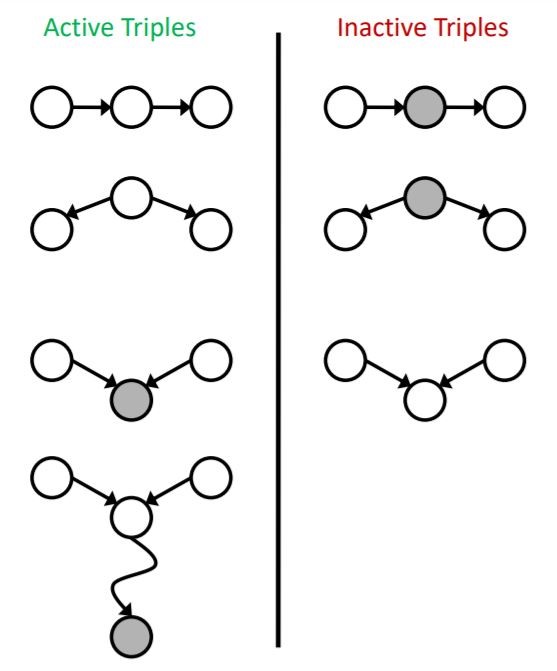
note that a single inactive triple makes a path inactive. but two RVs are independent if all paths between related nodes are inactive. So, if some paths were active, independence is not guaranteed.
Examples:
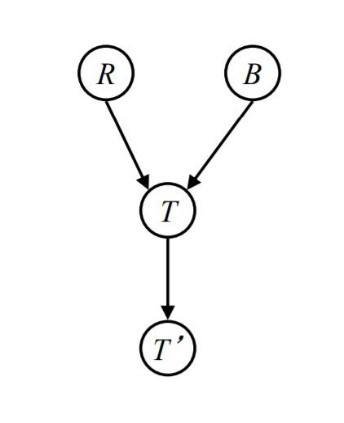
a. we want to check conditionally independence between $R$ and $B$ variables with different evidence.
b. we want to check conditionally independence between $L$ and $B$ variables with different evidence.
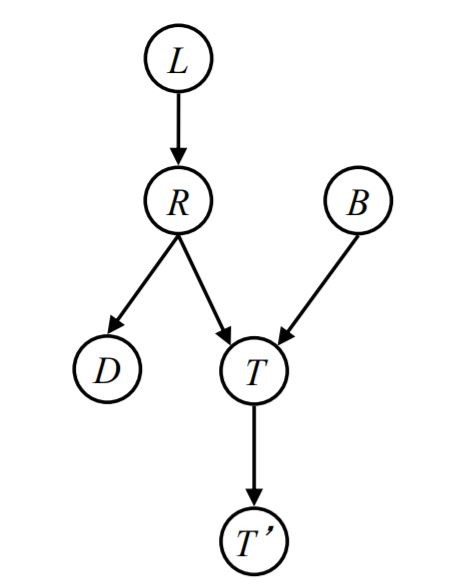
c. we want to check conditionally independence between $T$ and $D$ variables with different evidence.
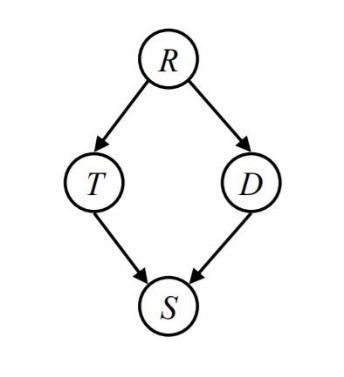
As you can see, With the help of this algorithm, sometimes it is possible to check the conditional independence of two random variables more easily. So, if we test the algorithm on all models, we get a list of conditional independence. but sometimes this list isn’t complete. because when we check conditional dependencies, some cases aren’t certain, and using this method alone, their independence cannot be recognized.
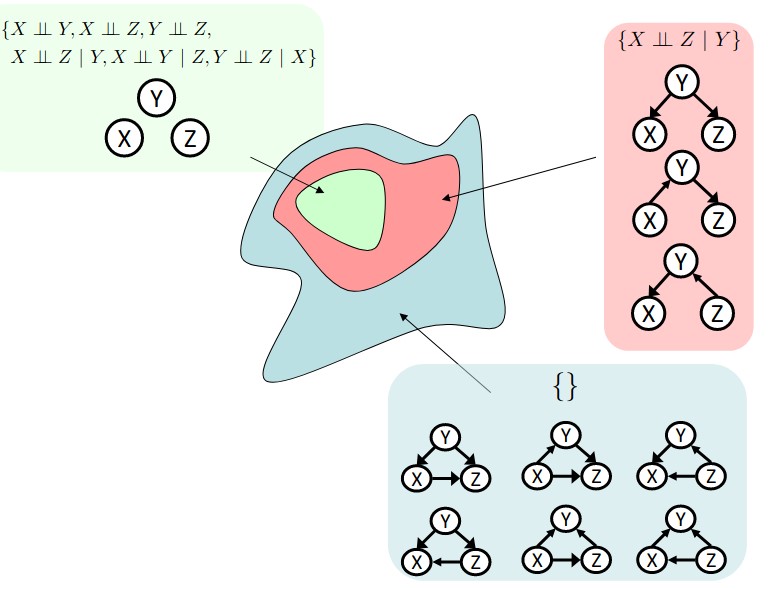
but in some cases, “d-separation” algorithm can find all dependencies. For example, in the figure below;
In a given graph topology, only certain joint distributions can be encoded. The graph structure guarantees certain (conditional) independence (There might be more independence). As the number of arcs increases, the probability that there is at least one active path between the two variables increases. Thus the independence of the variables decreases.
For example, in the figure below, different kind of dependence for triples is mentioned.
Through this lecture note, we saw that:
Joint distributions can be encoded efficiently using bayes' nets which simplifies calculations a lot compared to the classic joint distribution tables method.
Guaranteed independencies of distributions can be deducted from the bayesian net graph structure which weren't apparent at first. Moreover, using d-separation gives us precise conditional independence guarantees from the graph alone.
Even that isn't all. There may as well be more (conditional) independencies that are not detectable until we inspect the specific distributions.
Up until now, we saw how to build a bayes' net and how to find the independencies. The next step is to put these bayes' nets to use and infer probabilities from it. It's basically done by multiplying probabilities taken from every node on the path from top to the desired node. Read the next lecture note to learn all the details.
http://ce.sharif.edu/courses/00-01/1/ce417-1/resources/root/Slides/PPT/Session%2011_12.pptx
https://en.wikipedia.org/wiki/Bayesian_network
https://www.bu.edu/sph/files/2014/05/bayesian-networks-final.pdf
https://web.stanford.edu/class/archive/cs/cs221/cs221.1196/lectures/bayes1.pdf
https://www.cs.cmu.edu/~./awm/tutorials/bayesnet09.pdf

