
Parham Chavoshian
Author
Convolutional neural networks and their applications
Deep learning is a subfield of machine learning that deals with algorithms inspired by the structure and function of the brain. Deep learning is a subset of machine learning, which is a part of artificial intelligence (AI).

CNNs are models to solve deep learning problems. Suppose that you have high-dimensional inputs such as images or videos. If we want to use MLPs, 2 (or more) dimensional inputs need to be converted to 1-dimensional vectors. This conversion increases the number of trainable parameters exponentially. Also, one important thing in these data is locality, it means that for example in an image, you can find features in adjacent pixels (for example corners and edges) but, distant pixels can't give you efficient features. The solution for solving these problems is using CNNs.
A CNN architecture is formed by a stack of distinct layers that transform the input volume into an output volume through a differentiable function. A few distinct types of layers are commonly used:
In the following, you can see images of two simple famous CNNs.
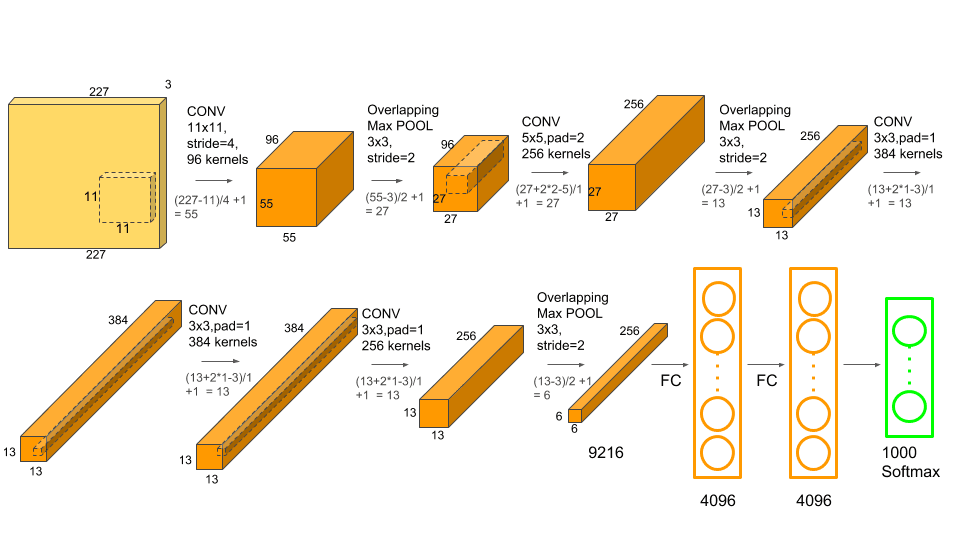
Fully Connected layers in neural networks are those layers where all the inputs from one layer are connected to every activation unit of the next layer. In most popular CNN models, the last few layers are fully connected layers that compile the data extracted by previous layers to form the final output. It is the second most time-consuming layer second to the Convolution Layer.

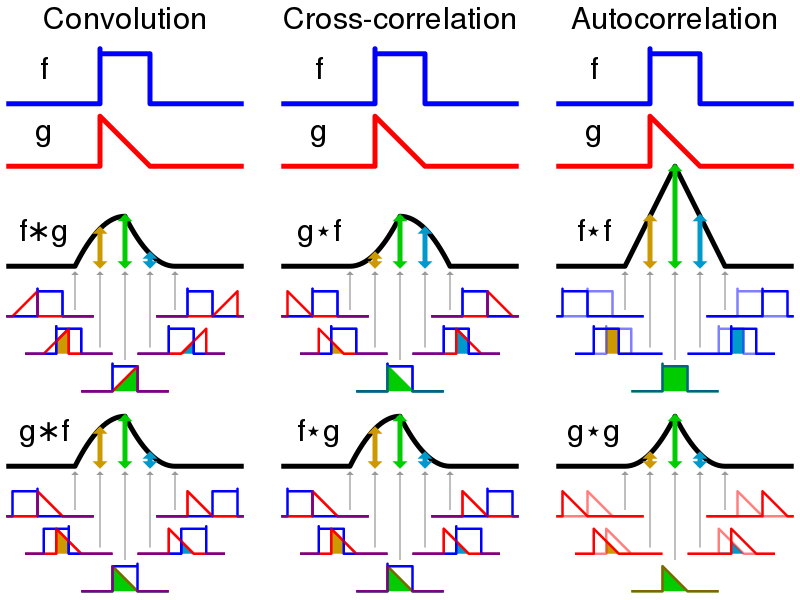
This layer is the main difference between CNNs and MLPs. Convolution in the word refers to two operators between two functions. In mathematics convolution is defined as below:
\((f * g)(t) := \int_{-\infty}^{\infty} f(\tau)g(t - \tau)d\tau\)
In this image, you can see an example for functions of convolution and two other similar operators.
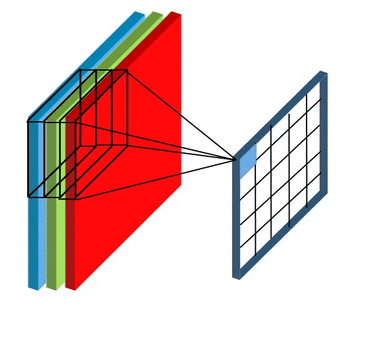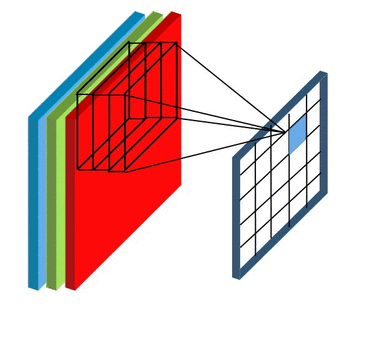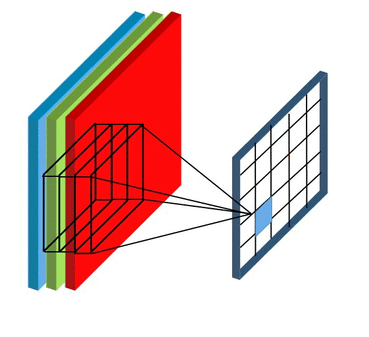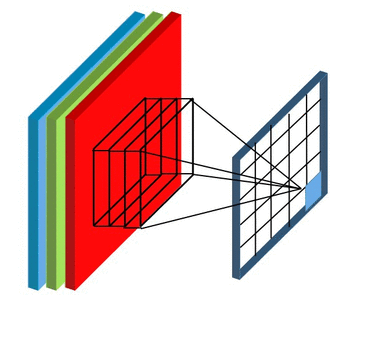
Here we’ll not talk about details, but convolutional layers are somehow enabling convolution operator on sub-matrices of the image. These layers have formed from some kernel with the same height, width, and depth. The number of these kernels is equal to the depth of the output. Also, the depth of each kernel must be equal to the depth of input. For example, if you have RGB data, your first convolutional layer kernels depth must be 3.
In the context of a convolutional neural network, convolution is a linear operation that involves the multiplication of a set of weights with the input. A convolution layer has formed by 1 or more of these operations that each of them called a kernel. All kernels have the same height, width, and depth. To find the output of the layer put the first kernel on the top-right of the input, calculate the output of the kernel, and put it as the first cell of a matrix. After that, move it to right, calculate again, and put the result in the second cell. When reaching the last column, move the kernel down. Do this until reaching the end of the image. We do this for all kernels and this is how make the output of the convolutional layer.
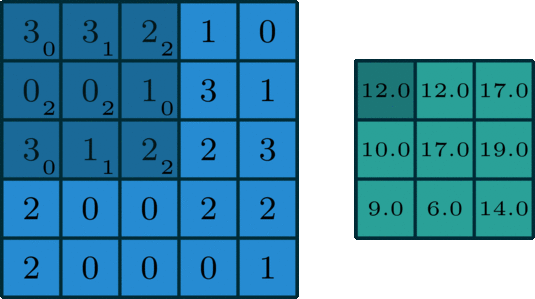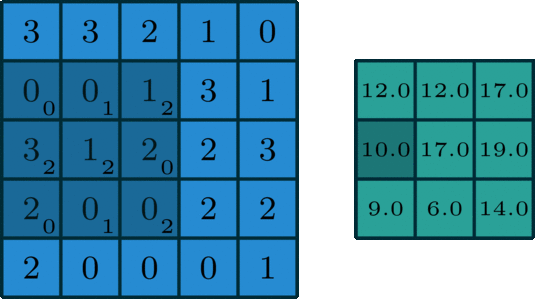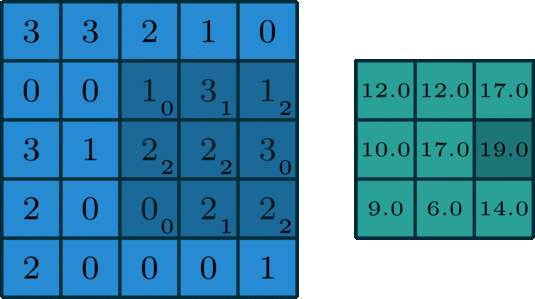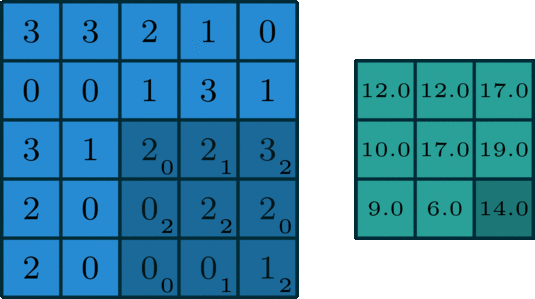
Similar to the Convolutional Layer, the Pooling layer is responsible for reducing the spatial size of the convolved feature. While a lot of information is lost in the pooling layer, it also has a number of benefits to the Convolutional Neural Network. They help to reduce complexity, improve efficiency, and limit the risk of overfitting. This is to decrease the computational power required to process the data by reducing the number of parameters in the input. It sweeps a filter across the entire input but that does not have any weights. Instead, the kernel applies an aggregation function to the values within the receptive field, populating the output array. There are two types of Pooling:

As you see, after applying convolutional layers, the size of the feature map is always smaller than the input. We have to do something to prevent our feature map from shrinking. This is where we use padding. Layers of zero-value pixels are added to surround the input with zeros so that our feature map will not shrink. By padding, we can control the shrinking of our inputs. Different padding modes are: * zeros(Default) * reflect * replicate or circular

As we said before, when you're applying a kernel to the image, you have to move the kernel along the image. But sometimes you prefer not to move one pixel every time and move the kernel more than one pixel. This is stride. The stride specifies how many kernels have to move each time.

An activation function is a function that is added to an artificial neural network in order to help the network learn complex patterns in the data. When compared with a neuron-based model that is in our brains, the activation function is at the end deciding what is to be fired to the next neuron. That is exactly what an activation function does in a neural network as well. It takes in the output signal from the previous cell and converts it into some form that can be taken as input to the next cell. The comparison can be summarized in the figure below.

The most important feature in an activation function is its ability to add non-linearity into a neural network. Here we describe six famous activation functions: - Relu(Rectified Linear Unit) : The rectified linear activation function or ReLU for short is a piecewise linear function that will output the input directly if it is positive, otherwise, it will output zero. It has become the default activation function for many types of neural networks because a model that uses it is easier to train and often achieves better performance. - Leaky ReLU: It is an attempt to solve the dying ReLU problem. Usually, the value of the slope in the negative range is 0.01 or so. - Sigmoid : The main reason why we use the sigmoid function is that it exists between (0 to 1). Therefore, it is especially used for models where we have to predict the probability as an output. Since the probability of anything exists only between the range of 0 and 1, sigmoid is the right choice. The function is differentiable. That means, we can find the slope of the sigmoid curve at any two points. The function is monotonic but the function’s derivative is not. - Tanh or hyperbolic tangent Activation Function : The advantage is that the negative inputs will be mapped strongly negative and the zero inputs will be mapped near zero in the tanh graph. The function is differentiable. The function is monotonic while its derivative is not monotonic. The tanh function is mainly used in classification between two classes. - Maxout : The Maxout unit is an activation function that is itself trained by our model. A single Maxout unit can be interpreted as making a piecewise linear approximation to an arbitrary convex function. A Maxout unit takes the maximum value among the values from n linear functions. The number of linear functions is determined beforehand. - ELU : Exponential Linear Unit or its widely known name ELU is a function that tends to converge cost to zero faster and produce more accurate results. ELU is very similar to RELU except for negative inputs. They are both in identity function form for non-negative inputs. On the other hand, ELU becomes smooth slowly until its output is equal to -α whereas RELU sharply smoothes.

As part of the optimization algorithm, the error for the current state of the model must be estimated repeatedly. This requires the choice of an error function, conventionally called a loss function, that can be used to estimate the loss of the model so that the weights can be updated to reduce the loss on the next evaluation. These are two famous loss functions:
in_channels: Number of channels in the input image
out_channels: Number of channels produced by the convolution
kernel_size: Size of the convolving kernel
stride: Stride of the convolution. Default: 1
padding: Padding added to all four sides of the input. Default: 0
dilation: Spacing between kernel elements. Default: 1
Interest in deep learning is continuing to increase. Reasons for this interest include deep learning’s capacity to
The number of times a phrase is searched on a search engine is a proxy for its popularity. You can see the frequency with which “Deep learning” was searched on Google below.

What's Next For Deep Learning?
No one knows!

