
Bahar Asadi
Author
Passive reinforcement learning algorithms and their applications
"... What we want is a machine that can learn from experience." -Alan Turing, 1947
At the beginning of the lecture note, we briefly introduce the RL algorithm. After that, we compare online models to offline models. Additionally, we compare different categories of learning methods based on the model. Then we use Direct Utility Estimation Method to estimate our factor based on sample values. Later, we introduce Temporal Difference Learning Algorithm to understand how the agent can gain experience and learn from the envirnment if it does not have enough knowledge. At the end of the discussion, there is a summary of different topics in RL which we have learned.
Reinforcement Learning is a subcategory of Machine Learning which can solve real-life problems. These problems involve learning what to do—how to
map situations to actions— to maximize a numerical reward signal. In this learning system, the system's actions influence its later inputs. Moreover, the learner is not told which actions to take but instead must discover
which actions yield the most reward by trying them out.
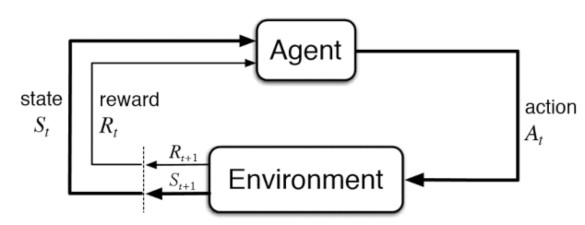
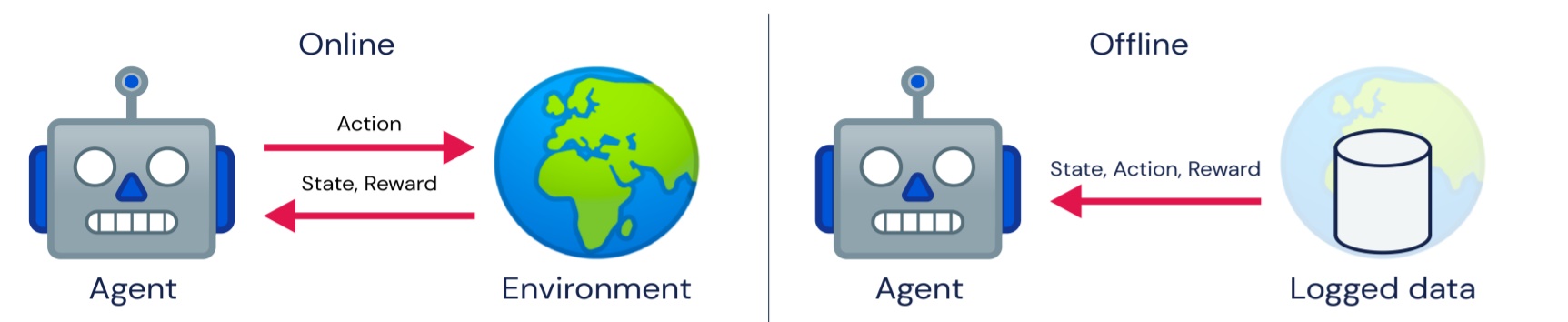
Overall, there are two learning methods—online and offline. In the online approach, the agent has no information about the environment. It gathers information by rewards and decides which states are good and which are bad and should be avoided. However, in the offline method, the agent has prior information, helping it decide on its actions based on the information and receive a less negative reward. Reinforcement learning (RL) is an MDP without $T$ and $R$, meaning it has no information on the environment. Thus, the learning method in RL is online.
RL systems can be divided into two categories: model-based and model-free
Model-based RL : This method tries to overcome the issue of a lack of prior knowledge to construct a functional representation of its environment. It solves the problem in two steps:
Learn imprical MDP model : In this model, the agent explores the environment and performs some actions to estimate the parameters of the model. These parameters are $\hat{T}(s, a, s')$ and $\hat{R}(s, a, s')$. First, it counts outcomes $s'$ for each $s,a$. Second, it normalizes the values to give an estimate of $\hat{T}(s,a,s')$. At last, it discovers each $\hat{R}(s,a,s')$ when it experiences $(s, a, s')$.
Solve the learned MDP: After estimating the missing parameters of the MDP model, the agent can solve the MDP by using various algorithms (e.g. Value Iteration) that are mentioned before.
Example: Assume that an agent wants to compute the expected age of students in one class. ($A$ is a random variable that represents the distribution of age) If the agent has the distribution of $A$, it can easily calculate the expectation according to $E[A] = \sum_{a} P(a).a$ . On the other hand, if the agent doesn't have the distribution over $A$, the problem must use Reinforcement Learning that can be solved with model-based or model-free RL.
* Model-based approach: In this algorithm, first we have to estimate $\hat{P}(a)$. The estimation is simple in this special example, but it can be complicated in real-world problems. We start exploring and getting samples and then We set $\hat{P}(a) = \frac{num(a)}{N}$. $num(a)$ is the number of occurrences of the age $a$. Finally, after finding the probability function, we can find the expectation with $E[A] \approx \sum_{a} \hat{P}(a).a$.
* Model-free approach: In this algorithm, there is no need to find $\hat{P}(a)$. After exploring the envirnoment and gathering samples, we can directly calculate the value of $E[A] = \frac{1}{N}\sum_{i} a_i$. Samples appear with accurate frequencies. As a result, we can be sure that this algorithm works efficiently.
Example: In this example, we are going to estimate $\hat{T}(s,a,s')$ and $\hat{R}(s,a,s')$ using model-based RL. In these kinds of questions, we need to fix the input policy $(\pi)$ and observe episodes to train the model and estimate the parameters. Each episode contains a series of movements with the same length (in this example the length of each episode is 3). After observing, we can estimate the possibility of each transition and the reward function for each movement.
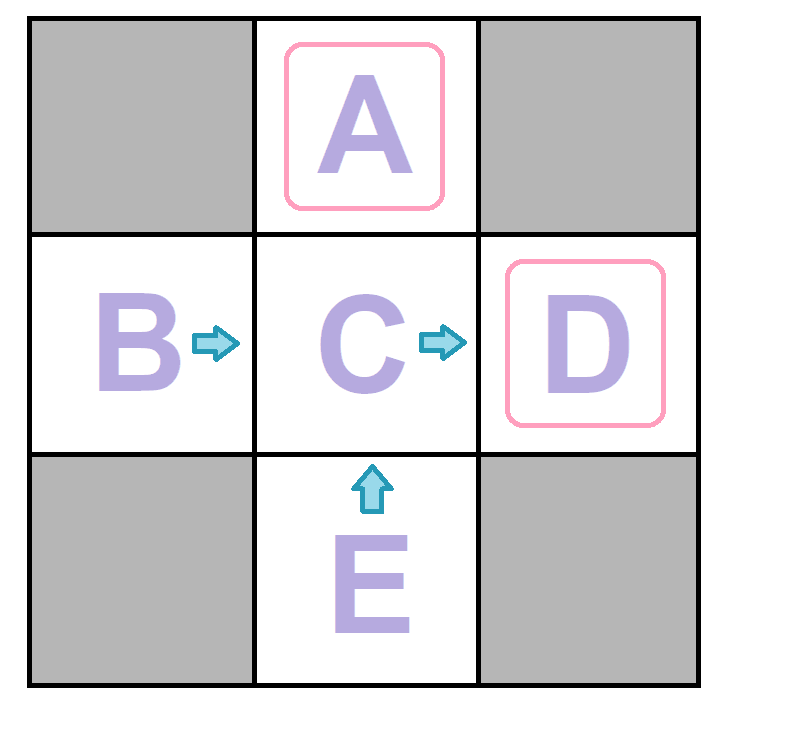
| Episode1 Episode2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| |||||||||
| C | east | D | -1 | C | east | D | -1 | ||
| D | exit | X | +10 | D | exit | X | +10 | ||
| Episode3 Episode4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| |||||||||
| C | east | D | -1 | C | east | A | -1 | ||
| D | exit | X | +10 | A | exit | X | +10 | ||
After sampling, in order to estimate $\hat{T}$ for each $(s,a,s')$, we have to count the number of all movements that start from $s$ and have the action $a$ and go to state $s'$. After that we have to divise this count to the number of movements that start from $s$ and have the action $a$. For example:
* $T(B, east, C) = \frac{2}{2} = 1$
* $T(C, east, D) = \frac{3}{4} = 0.75$
In addition, we can estimate $\hat{R}(s,a,s')$ for each movement in all episodes. We have to get the average of the reward for all tuples of $(s,a,s')$. For example:
* $$R(B, east, C) = \frac{-1-1}{2} = -1$$
* $$R(D, exit, x) = \frac{10+10+10}{3} = 10$$
Question: What is the problem of above model-based algorithm?
If the number of states are large, the number of required samples to train the model will be $O((|S|)^2.|A|)$. In other words, we need many episodes to be able to train the model properly.
According to learning policy, there are two types of RL: Passive Reinforcement Learning, Active Reinforcement Learning. In below, we explain both methods.
Passive reinforcement learning is when we want an agent to learn about the utilities of various states under a fixed policy. The learned policy will be different from the original fixed policy. Direct Utility Estimation and Temporal Difference Learning are two passive RL algorithms.
Active reinforcement learning is when the agent's policy is not fixed and can change during the time of training. In this method exploration and exploition are done. Exploration refers to trying new actions that are rarely done and checking if they have a bigger reward. Exploition refers to keep doing the optimal action at each state. Q-learning is one of the active RL algorithms.
Policy evaluation computes the value functions for a policy $\pi$ using the Bellman equations. $$ V^{\pi}_0 (s) = 0 $$ $$ V^{\pi}_{k+1} \leftarrow \sum_{s'}T(s, \pi(s), s')[R(s, \pi, s') + \gamma V^{\pi}_k(s') $$ In fact, simplified Bellman updates calculate V for a fixed policy: * Each round, replace V with a one-step-look-ahead layer over V * This approach fully exploited the connections between the states
Definition: In this method, the agent executes a sequence of trials. Each trial gives a sample value and the agent estimates the utility based on the samples values. This can be calculated as running averages of sample values.
Direct utility estimation (model-free)
Reward-to-go of a state $s$
Key: use observed reward-to-go of the state as the direct evidence of the actual expected utility of that state
Suppose we have a 4x3 grid as the environment in which the agent can move either Left, Right, Up or Down(set of available actions). An example of a run:
$(1,1) _{-0.04} \rightarrow (1,2) _{-0.04} \rightarrow (1,3) _{-0.04} \rightarrow (1,2) _{-0.04} \rightarrow (1,3) _{-0.04} \rightarrow (2,3) _{-0.04} \rightarrow (3,3) _{-0.04} \rightarrow (4,3) _{+1}$
The total reward starting at (1,1) is 0.72. We call this a sample of the observed-reward-to-go for (1,1).
For (1,2) there are two samples for the observed-reward-to-go (assuming $\gamma$=1):
$(1,2) {-0.04}\rightarrow (1,3) \rightarrow (1,2) {-0.04} \rightarrow (1,3) \rightarrow (2,3) {-0.04} \rightarrow (3,3) [Total:0.76] $ } \rightarrow (4,3) _{+1
Direct Utility Estimation keeps a running average of this observed reward-to-go for each state
Eg. for state (1,2), it stores $\frac{(0.76+0.84)}{2}=0.8$
Thus, at the end of each sequence, the algorithm calculates the observed reward-to-go for each state and updates the estimated utility for that state accordingly, just by keeping a running average for each state in a table. In the limit of infinitely many trials, the sample average will converge to the true expectation in the following Equation.
$V^\pi (s) = E [\sum_{t = 0}^{\infty } \gamma^t R (S_{t})]$
Direct utility estimation succeeds in reducing the reinforcement learning problem to an inductive learning problem, about which much is known. Unfortunately, it misses a very important source of information, namely, the fact that the utilities of states are not independent! The utility of each state equals its own reward plus the expected utility of its successor states. That is, the utility values obey the Bellman equations for a fixed policy (the following Equation)
$V^\pi (s) =R(S)+\gamma \sum_{\acute{s}} P(\acute{s}|s,\pi(s)) U^\pi(\acute{s})$
And now it is good to see an example. The purpose of this question is to estimate the returns.
Example: Calculate the return of each state according to the figure below and the given episodes.($\gamma =1$)
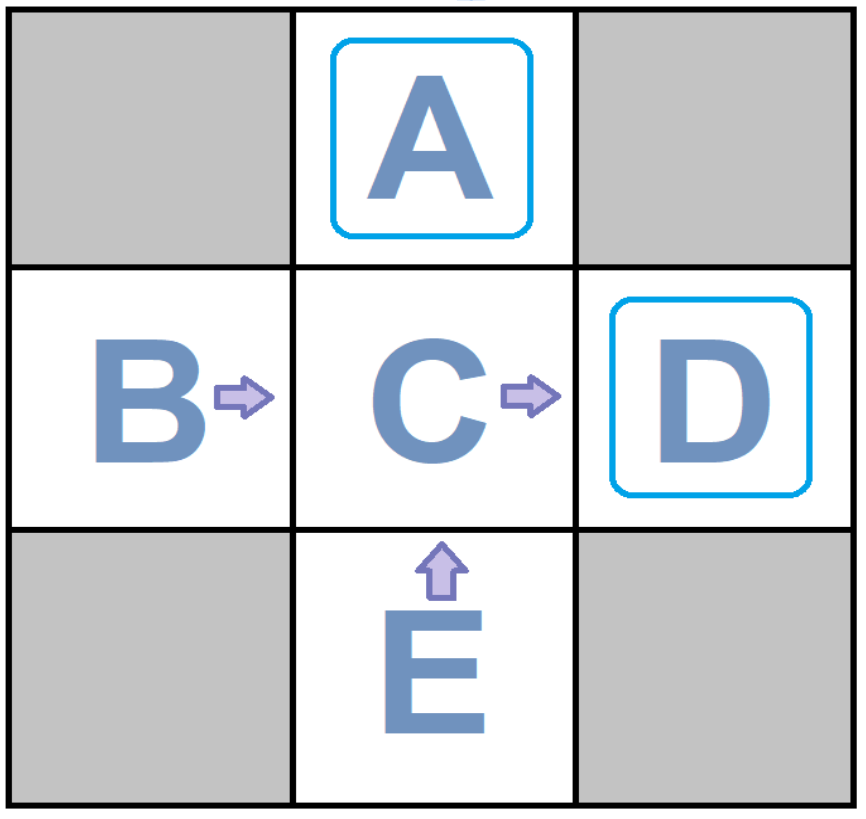
| Episode1 Episode2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| |||||||||
| C | east | D | -1 | C | east | D | -1 | ||
| D | exit | X | +10 | D | exit | X | +10 | ||
| Episode3 Episode4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| |||||||||
| C | east | D | -1 | C | east | A | -1 | ||
| D | exit | X | +10 | A | exit | X | +10 | ||
Now we solve this example:
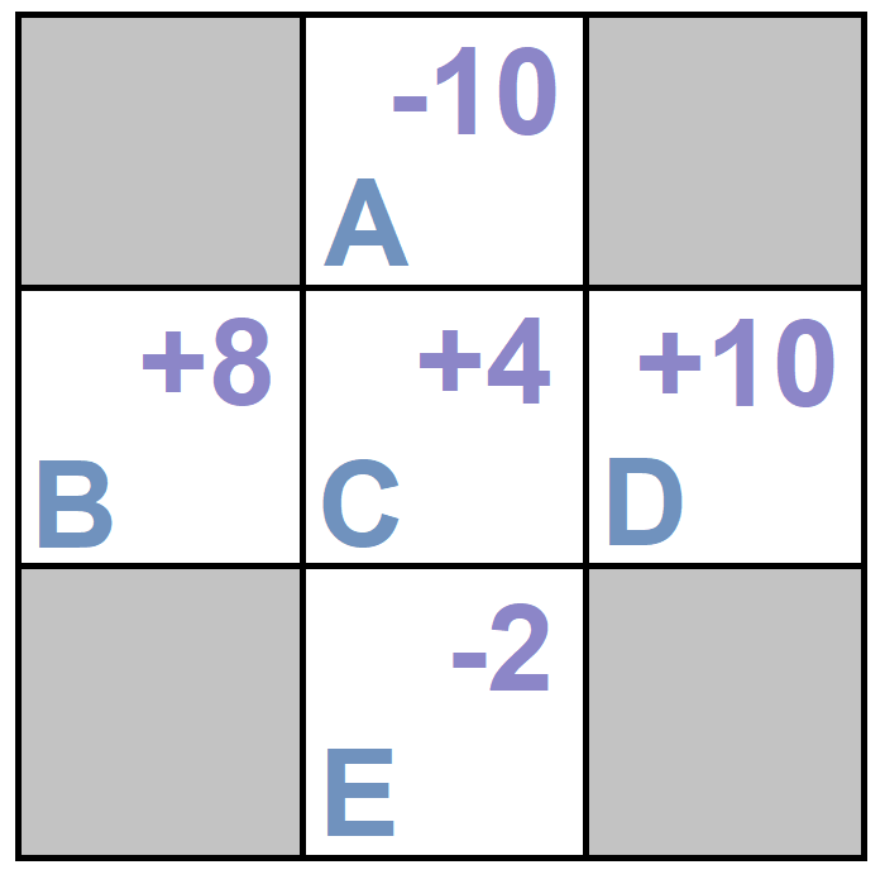
According to the question, you have to estimate the return seen in each state.
According to the given episodes and $\gamma = 1$, you should look for your state in the first column of each episode, then average the numbers(s) in the last column, from that point until the end.
Pay attention to the solution:
state A: You can see A just in the fourth episode $\rightarrow$ $\frac{(+10)}{1}=+10$
state B: You can see B in the first and second episodes $\rightarrow$
$\frac{( -1 -1 + 10) + ( -1 -1 + 10 ) }{ 2} = +8$
state C: You can see C in all episodes $\rightarrow$ $\frac{( -1 + 10 )+( -1+10 ) + ( -1 + 10 )+( -1 -10 )} {4} = +4$
state D: You can see D in The first three states $\rightarrow$ $\frac{(+10+10+10)}{3} =+10$
If you pay more attention, you will notice that the problem with this method is, we can move to C both from E and B, but we find very different values for them. The reason for this difference is the lack of sample. we also express the values of each state independent from other states.
Easy to understand
Does not require any knowledge of T, R
Computes the correct average values, using just sample transitions
Wastes information about state connections
Each state must be learned separately
Takes a long time to learn
Converges very slowly
Why?
- Does not exploit the fact that utilities of states are not independent
- Utilities follow the Bellman equation
$V_{\pi} (s) =R(S)+\gamma \sum_{\acute{s}} T(s,\pi(s),{\acute{s}})V_{\pi}({\acute{s}})$
Question: How to approximate E[X] (The right side of the equation below) based on model-free learning?
$V^\pi_{k+1}(s) \leftarrow \sum_{{\acute{s}}} T(s,\pi(s),\acute{s} )[R(s,\pi(s),\acute{s} )+\gamma V^\pi_{k} ]$We cannot use this equation directly since we do not have T and R, but we can use the average of the returned value ($[R(s,\pi(s),\acute{s} )+\gamma V^\pi_{k} ]$). So we can change our formula to the following form.
$V^\pi (s) \approx \frac{1}{N} \sum [R(s,\pi(s),\acute{s})+\gamma V^\pi(\acute{s})]$If you pay a little attention, you will notice that there is a problem, so what is the problem with this approach? In one state, an action cannot be repeated N times, because you move on to another state as soon as an action is taken and it will be physically impossible be able to perform another action in the same state. Now, what is the solution?
You can take the average in more than one shot, for example, take different actions in multiple episodes and update the average as you arrive to the desired state. For example, if the average is $\varphi$ up to this point, the updated average would be:
$\varphi_{new} = \varphi n + \frac {x} {n+1}$In which $n$ is the number of data you have collected.
Definition: TD is an agent learning from an environment through episodes with no prior knowledge of the environment.
It learns from trial and error.
TD takes a model-free or unsupervised learning approach.
TD tries to predict the immediate reward and the reward at the next moment instead of calculating the total future reward.
The key concept of the a TD agent: ($R$ is the reward function)
$$R_{t} = r_{t+1} + \gamma r_{t+2} + \gamma ^{2} r_{t+3} + ... = \sum_{k = 0}^{\infty }\gamma ^{k} r_{t + k + 1}$$In fact, TD learning tries to answer the question of how to compute this weighted average without the weights, cleverly doing so with an exponential moving average. In this equation reward at time t is a combination of discounted rewards in the future which shows that future rewards are valued less.
TD agent error:
$$ E_{t} = V^{\pi ^ *}_{t} - V^\pi_{t} $$\ $$= r_{t+1} + \sum_{k = 1}^{\infty }\gamma ^{k} r_{t + k + 1} - V^ \pi_{t} $$\ $$= r_{t+1} + \gamma \times \sum_{k = 1}^{\infty }\gamma ^{k-1} r_{t + k + 1} - V^\pi_{t} $$\ $$= r_{t+1} + \gamma \times \sum_{k = 0}^{\infty }\gamma ^{k} r_{(t + 1) + (k + 1)} - V^\pi_{t}$$\ $$= r_{t+1} + \gamma \times \sum_{k = 0}^{\infty }\gamma ^{k} r_{(t + 1) + (k + 1)} - V^\pi_{t}$$\ $$= r_{t+1} + \gamma \times V^\pi_{t+1} - V^\pi_{t}$$
Updating the value: ($\alpha$ is learning rate)
$$V^\pi_{t} \leftarrow V^\pi_{t} + \alpha \times E_{t} = V^\pi_{t} + \alpha \times( r_{t+1} + \gamma \times V^\pi_{t+1} - V^\pi_{t})$$The pseudocode of the process is shown below.
function PASSIVE-TD-AGENT(percept) returns an action
inputs: percept, a percept indicating the current state s' and rewarl signal r'
persistent: pi, a fixed policy
V, a table of values(utilities), initially empty
N_{s}, a of frequencies for states, initially zero
s, a, r, the previous state, action, and reward, initially null
if s' is new then V[s'] = r'
if s is not null then :
increment N_{s}[s]
V[s] = V[s] + alpha * (N_{s}[s])(r + gamma * V[s'] - V[s])
if s'.TERMINAL? then s, a, r = null
else :
s = s'
a = pi[s']
r = r'
return a
It is good to mention that because rare transitions occur only rarely, the average of value function will converge to the correct value.
Example
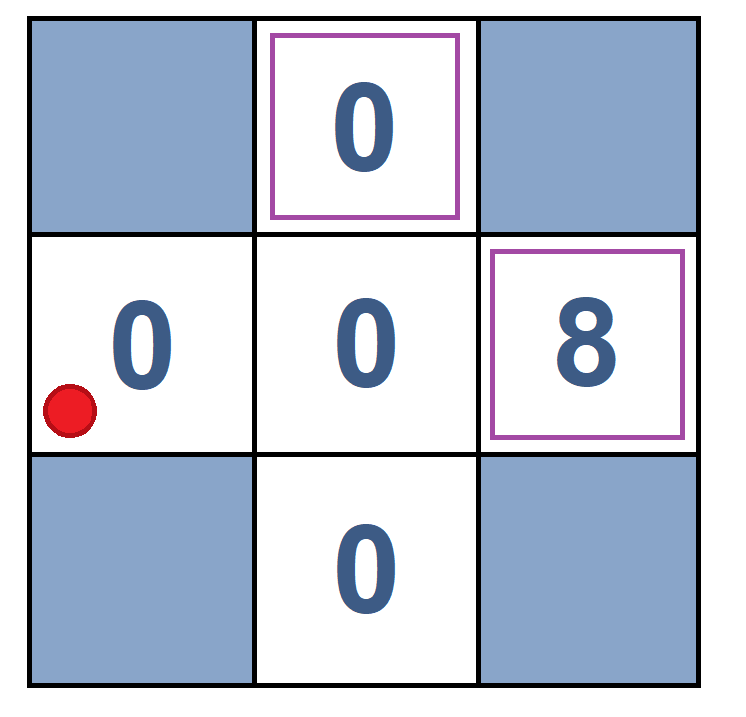
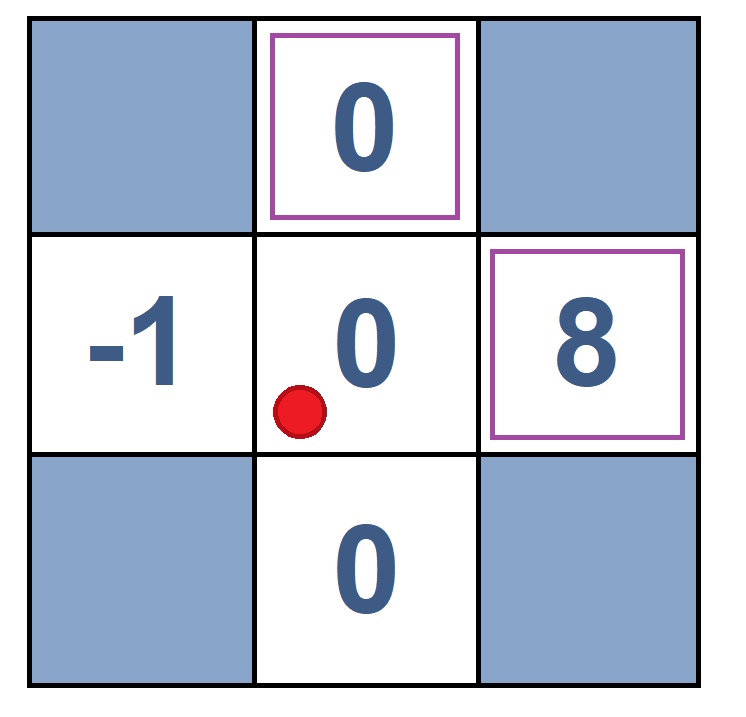
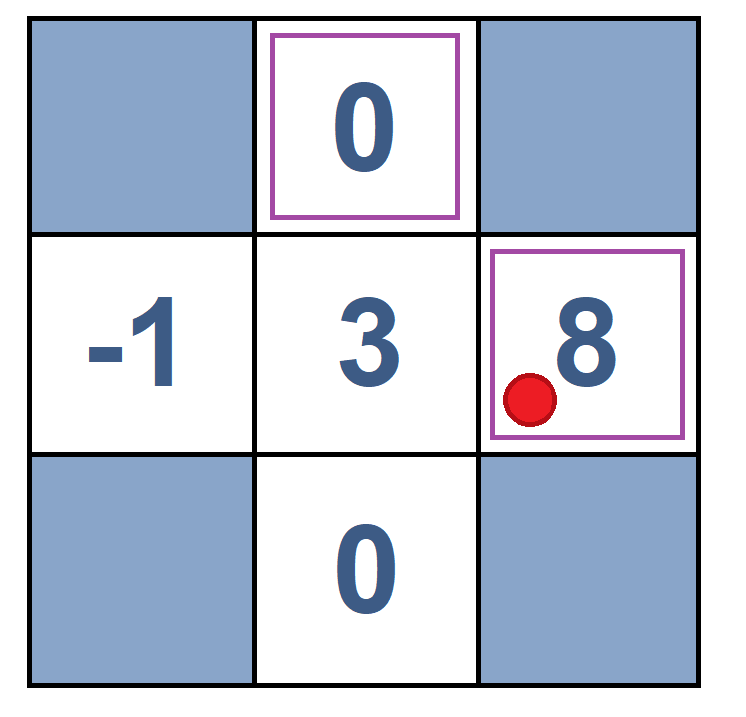
Consider the following grid with $\gamma = 1$ and $\alpha = 1/2$. We have the initial $V^{\pi}(x_i)$ in State 1. We want to calculate $V^{\pi}(B)$ and $V^{\pi}(C)$ after sampling and two moves.
| State 1 | Move 1(B, east, C, -2) | State 2 | Move 2 (C, east, D, -2) | State 3 |
|---|---|---|---|---|
 |
 |
 |
The formula is: $$V^\pi_{t} \leftarrow V^\pi_{t} + \alpha \times E_{t} = V^\pi_{t} + \alpha \times( r_{t+1} + \gamma \times V^\pi_{t+1} - V^\pi_{t})$$ Calculations:
$V^{\pi}(B) = ?$ $V^{\pi}(B) \leftarrow V^{\pi}(B) + \alpha \times (-2 + \gamma \times V^{\pi}(C))$ $\rightarrow V^{\pi}(B) = 0 + 1/2 \times (-2 + 1 \times 0) = -1$ $V^{\pi}(C) = ?$ $V^{\pi}(C) \leftarrow V^{\pi}(C) + \alpha \times (-2 + \gamma \times V^{\pi}(D))$ $\rightarrow V^{\pi}(C) = 0 + 1/2 \times (-2 + 1 \times 8) = 3$For better understanding and seeing how a TD agent acts in the environment, see the code below, which belongs to "HalfCheetah-v2", a TD agent.
import numpy as np
from gym import utils
from gym.envs.mujoco import mujoco_env
class HalfCheetahEnv(mujoco_env.MujocoEnv, utils.EzPickle):
def __init__(self):
mujoco_env.MujocoEnv.__init__(self, "half_cheetah.xml", 5)
utils.EzPickle.__init__(self)
def step(self, action):
xposbefore = self.sim.data.qpos[0]
self.do_simulation(action, self.frame_skip)
xposafter = self.sim.data.qpos[0]
ob = self._get_obs()
reward_ctrl = -0.1 * np.square(action).sum()
reward_run = (xposafter - xposbefore) / self.dt
reward = reward_ctrl + reward_run
done = False
return ob, reward, done, dict(reward_run=reward_run, reward_ctrl=reward_ctrl)
def _get_obs(self):
return np.concatenate(
[
self.sim.data.qpos.flat[1:],
self.sim.data.qvel.flat,
]
)
def reset_model(self):
qpos = self.init_qpos + self.np_random.uniform(
low=-0.1, high=0.1, size=self.model.nq
)
qvel = self.init_qvel + self.np_random.standard_normal(self.model.nv) * 0.1
self.set_state(qpos, qvel)
return self._get_obs()
def viewer_setup(self):
self.viewer.cam.distance = self.model.stat.extent * 0.5
The video of this agent in the environment is shown below.
https://user-images.githubusercontent.com/62206142/148566163-089a2a3c-4361-4997-b956-d4e790cf1cbd.mp4
All we want is to find the best policy that suits us. Although TD agent finds the value of each state (A value that converges to the real value during the time), it cannot find the best policy because for finding that and doing one-step expectimax, $T$ and $R$ functions are needed. However, in RL, they are not available. Therefore, a new method is required, called Q-Learning.
In this lecture note, we tried to cover some topics of RL. First, we talked about RL itself and gave the definition. Then, we mentioned various types of RL and their differences. In the end, we tried to cover two methods of learning used in RL. There is a summary of these methods and usages of RL in the following.
Here are prime reasons for using Reinforcement Learning:
Here are applications of Reinforcement Learning:
[1] Learning to Run: Example of Reinforcement Learning. https://deepsense.ai/learning-to-run-an-example-of-reinforcement-learning/
[2] Reinforcement Learning Applicants. https://neptune.ai/blog/reinforcement-learning-applications
[3] What is Q-Learning. https://www.simplilearn.com/tutorials/machine-learning-tutorial/what-is-q-learning
[4] Reinforcement Learning and Python. https://www.youtube.com/watch?v=-daMfdwpmAg
[1] Passive Reinforcement Learning. https://kcir.pwr.edu.pl/~witold/ai/mle_rl_h.pdf (visited: 2/1/2022)
[2] Active vs Passive Learning. Shweta Bhatt. https://towardsdatascience.com/explaining-reinforcement-learning-active-vs-passive-a389f41e7195 (visited: 2/1/2022)
[3] Active and Passive Learning. Philipp Koehn. https://www.cs.jhu.edu/~phi/ai/slides/lecture-reinforcement-learning.pdf (visited: 25/12/2021)
[4] Model-Based vs. Model-Free RL. Russell and Norvig. https://web.engr.oregonstate.edu/~xfern/classes/cs434/slides/RL-1.pdf (visited: 6/1/2022)
[5]Online vs Offline Learning. Banghua Zhu, Cong Ma, Jiantao Jiao, Paria Rashidinejad. https://congma1028.github.io/Publication/OfflineRL/OfflineRL.pdf (visited: 7/1/2022)
[6]Direct Utility Estimation. Oregon State University. https://web.engr.oregonstate.edu/~xfern/classes/cs434/slides/RL-1.pdf (visited: 4/1/2022)
[7]Direct Utility Estimation. Carnegie Mellon University. https://www.cs.cmu.edu/~arielpro/15381f16/c_slides/781f16-12.pdf (visited: 5/1/2022)
[8]Example of Direct Utility Estimation. Shweta Bhat. https://towardsdatascience.com/explaining-reinforcement-learning-active-vs-passive-a389f41e7195 (visited: 5/1/2022)
[9] Temporal Difference Learning. Andrew Barto. http://www.scholarpedia.org/article/Temporal_difference_learning (visited: 1/1/2022)
[10] Temporal Difference Learning. Andre Violante. https://medium.com/@violante.andre/simple-reinforcement-learning-temporal-difference-learning-e883ea0d65b0 (visited: 1/1/2022)
[11] Temporal Difference Learning. Viet Hoang Tran Duong. https://towardsdatascience.com/intro-to-reinforcement-learning-temporal-difference-learning-sarsa-vs-q-learning-8b4184bb4978 (visited: 3/1/2022)
[12] Temporal Difference Learning. Henry AI Labs. https://www.youtube.com/watch?v=L64E_NTZJ_0 (visited: 27/12/2021)
[13] Sutton, Richard. Reinforcement Learning: An Introduction. London : The MIT Press (visited: 6/1/2022)
[14] HalfCheetah-v2. James L. https://www.youtube.com/watch?v=TpWXyauJ3M8 (visited: 5/1/2022)
[15] HalfCheetah-Code. https://github.com/openai/gym/blob/master/gym/envs/mujoco/half_cheetah.py (visited: 5/1/2022)

