
Karaneh Keypour
Author
Q-learning, active reinforcement learning, epsilon-greedy exploration, and approximate Q-learning
You’ve probably seen how a dog trainer gives a trait to the dogs after they complete a task successfully. That trait is a reward to the brain, and says “Well done! You are going in the right direction.” So after that, the brain tries to do that again to get more rewards. This way the dogs will learn and train themselves. This is sort of what happens in Reinforcement Learning(RL). Reinforcement learning (RL) is an area of machine learning concerned with how intelligent agents should take actions in an environment to maximize the reward by taking a series of actions in response to a dynamic environment. It is the science of making optimal decisions using experiences.
RL algorithms have 2 main types. model-based and model-free. A model-free algorithm doesn’t use or estimate the dynamics (transition and reward functions) of the environment for estimating the optimal policy. Whereas, a model-based algorithm uses both for that. Q-learning is a model-free reinforcement learning algorithm.
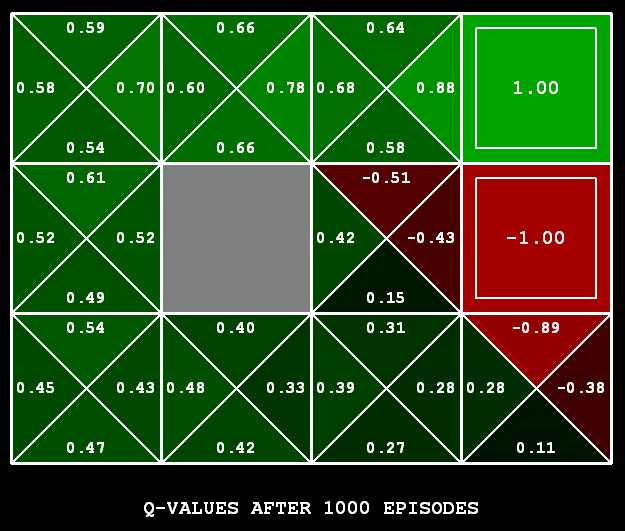
Q-learning is a model-free reinforcement learning algorithm to learn the value of an action in a particular state. It is a values-based learning algorithm. Values-based algorithms update the value function based on an equation. Q-learning is an off-policy learner, which means it learns the value of the optimal policy independently of the agent’s actions. In other words, it converges to optimal policy eventually even if you are acting sub-optimally. Q-learning is a sample-based q-value iteration method and in it, you Learn $Q(s,a)$ values as you go:
In active RL, an agent needs to decide what to do as there’s no fixed policy that it can act on. Therefore, the goal of an active RL agent is to act and learn an optimal policy. An agent interacts with the environment either by exploring or exploiting. Exploration is all about finding more information about an environment, whereas exploitation is exploiting already known information to maximize the rewards.
Say you go to the same restaurant every day. You are exploiting. But on the other hand, if you search for a new restaurant every time before going to any one of them, then it’s exploration. Exploration is very important for the search for future rewards which might be higher than the near rewards.

The tradeoff between exploration and exploitation is fundamental. the simplest way to force exploration is using epsilon greedy strategy. This method does a random action with a small probability of $\epsilon$ (exploration) and with a probability of $(1 - \epsilon)$ does the current policy action (exploitation). The problem with random actions is that you do eventually explore the space, but keep thrashing around once learning is done. one solution is to start with a higher $\epsilon$ rate and as the agent explores the environment, the ϵ rate decreases and the agent starts to exploit the environment.
Another solution is to use exploration functions. For example, this function can take a value estimate u and a visit count n, and return an optimistic utility, e.g. $f(u,n) = v + \frac{k}{n}$ . we are counting how many times we did some random action. if it had yet to reach a fixed amount, we should try it more often and if it doesn't return a good output we should just stop exploring it. So we’ll use a modified Q-update:
$$Q(s,a) \leftarrow \alpha R(s,a,s^{\prime}) + \gamma \max_{a^{\prime}} f(Q(s^{\prime},a^{\prime}),N(s^{\prime},a^{\prime}))$$in the above equation, k is fixed. Q is the optimistic utility which is given to f as v. and n is the number of times we visited s' after doing action a' starting from s. which means when the n is low we get to try those actions more often.
Even though most of the RL algorithms we discussed reach optimal policy, they still make mistakes along the way. Regret is a measure of the total mistake cost, the difference between rewards, and optimal rewards. Minimizing regret goes beyond learning to be optimal so it requires optimally learning to be optimal!
Basic Q-learning keeps a table of all Q-values but in real-world situations, there are too many states to visit and hold their Q-values. Instead, we can use function approximation, which simply means using any sort of representation for the Q-function other than a lookup table. The representation is viewed as approximate because it might not be the case that the true utility function or Q-function can be represented in the chosen form.
One way of using this is to use a feature-based representation in which we describe a state using a vector of features. In this method, we represent a linear combination of these features and try to learn $\omega_i$s so that the Q function is near the main Q-value.
$$V(s) = \omega_1f_1(s) + \omega_2f_2(s) + ... + \omega_nf_n(s)$$ $$Q(s,a) = \omega_1f_1(s,a) + \omega_2f_2(s,a) + ... + \omega_nf_n(s,a)$$To learn and update $\omega_i$s, we have a method that is similar to the method we had for updating Q-values in basic Q-learning:
$$\omega_m \leftarrow \omega_m + \alpha [r + \gamma \max_aQ(s^{\prime},a^{\prime}) - Q(s,a)] f_m(s,a)$$Q-Learning is a basic form of Reinforcement Learning which uses Q-values (action values) to iteratively improve the behavior of the learning agent.
Q-values are defined for states and actions. $Q(s, a)$ is an estimation of how good is it to take the action $a$ at the state $s$. This estimation of $Q(s, a)$ will be iteratively computed using the temporal difference update.
This update rule to estimate the value of Q is applied at every time step of the agent's interaction with the environment.
At every step of the transition, the agent from a state takes an action, observes a reward from the environment, and then transits to another state. If at any point in time the agent ends up in one of the terminating states that means there is no further transition possible. This is said to be the completion of an episode.
$\epsilon$-greedy policy is a very simple policy of choosing actions using the current Q-value estimations.
Active learning is a special case of machine learning in which a learning algorithm can interactively query a user (or some other information source) to label new data points with the desired outputs.
Unlike passive learning which just executes the policy and learns from experience, here we are using active reinforcement learning in which the agent learns the optimal policy by taking actions in the world finding out what is happening, and then improving the policy iteratively.
To read more about reinforcement learning, Q-learning, active and passive RL and much more, you can visit links below:

