
Alireza Tajmirriahi
Author
A short introduction to big data concepts, distributed data processing, and the role of tools such as Apache Spark in machine learning workflows.
Have you ever wondered how much data (in the form of texts, phone calls, videos, emails, searches, etc.) do we generate only when using our smartphones? Approximately 40 exabytes (40 million terabytes) of data gets generated every month by a single smartphone user! Now have fun multiplying it by 5 billion (and counting) users :)
Traditional computing systems are no longer capable of handling this amount of data which we call Big Data.
In the following sections we learn what data should we call Big Data, learn about some applications, and get familiar with some tools and techniques which are utilized to store and process that data.
In the end, some extra links are provided for further studying the subjects discussed.

A piece of data is classified as Big Data regarding to the concept of a bunch of Vs. In order to understand them, consider health care industry and medical records as an example:
Various frameworks are developed to ease the processing and storage of Big Data such as Cassandra, Apache Hadoop, and Apache Spark. But first, let's talk about a rather new parallel processing model designed to deal with some of Big Data challenges called MapReduce.
MapReduce is a software framework and programming model used for processing huge amounts of data which comprises two phases, Map and Reduce. Map tasks deal with splitting and mapping of data while Reduce tasks shuffle and reduce the data. The following image pretty much sums up the MapReduce architecture in Hadoop.

Apache Hadoop is a software platform that manages data processing and storage for big data applications. Hadoop works by distributing large data sets and analytics jobs across nodes in a computing cluster, breaking them down into smaller workloads that can be run in parallel. Hadoop is capable of running MapReduce programs written in various languages.
The programs of Map Reduce in cloud computing are parallel in nature, thus are very useful for performing large-scale data analysis using multiple machines in the cluster. The benefits of using Hadoop are scalability, resilience and flexibility.
Hadoop divides the job into tasks. The types of tasks are Map tasks (Splits & Mapping) and Reduce tasks (Shuffling, Reducing) as mentioned above. The complete execution process (execution of Map and Reduce tasks) is controlled by two types of entities called
For every job submitted for execution in the system, there is one Jobtracker that resides on Namenode and there are multiple tasktrackers which reside on Datanode.

One of the main challenges of Hadoop architecture is performance. Hadoop uses frequent reads and writes to disk to perform computations, which is time-consuming and inefficient compared to frameworks that aim to store and process data in memory as much as possible, like Apache Spark™.
Apache Spark™ is a general-purpose & lightning fast cluster computing platform. In other words, it is an open source, wide range data processing engine. That reveals development API’s, which also qualifies data workers to accomplish streaming, machine learning or SQL workloads which demand repeated access to data sets. However, Spark can perform both batch processing and stream processing. The main website provides a very well overview of its capabilities. Spark also has a strong documentation that helps you get started.
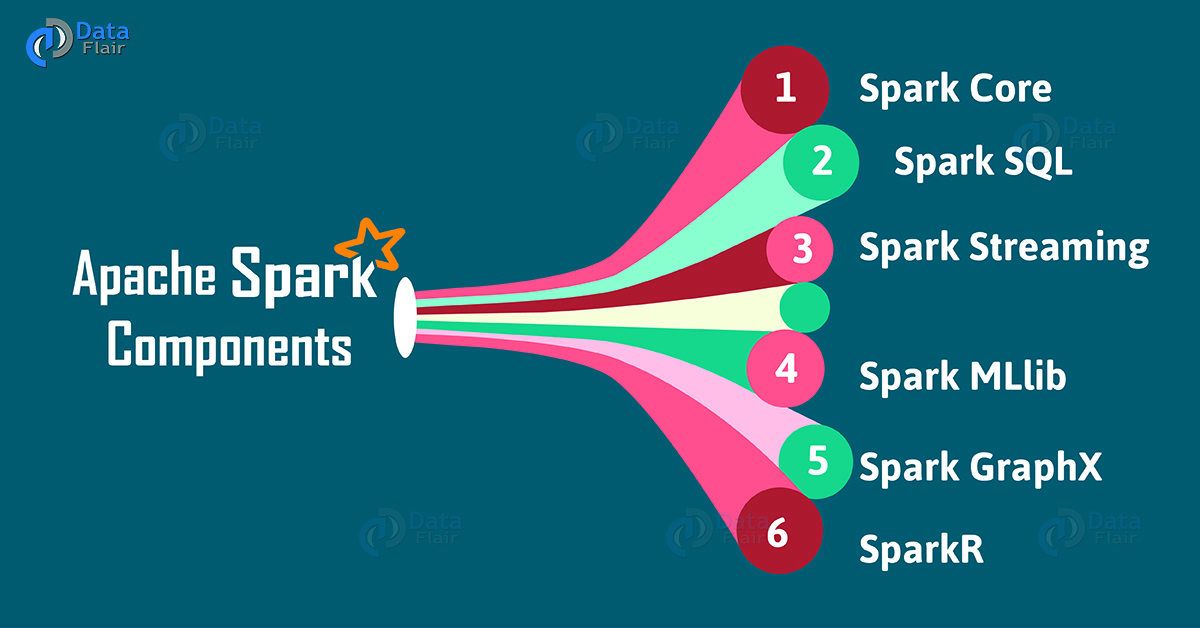
Moreover, it is designed in such a way that it integrates with all the Big data tools. Like spark can access any Hadoop data source, also can run on Hadoop clusters. Furthermore, Apache Spark extends Hadoop MapReduce to the next level. That also includes iterative queries and stream processing.
Although, there is one spark’s key feature that it has in-memory cluster computation capability. Also increases the processing speed of an application. This blog by Data Flair provides a comprehensive tutorial on Spark which is highly recommended for those interested.
In this section we finally try to get our hands dirty and gain a perspective on how a spark program is written. There are many options like Scala, Java, R and Python and we naturally choose PySpark to proceed. Although some of the resources which we introduce provide examples in all possible languages.
spark-submit) which can be useful in the Spark Shell.Two other great tutorials using some other docker image are provided here (Medium) and here (Towards Data Science). You could also use Tutorialspoint to learn every feature that PySpark offers.
These links and videos below help you get started and learn about basic concepts more deeply and then install and run a framework (e.g. Spark) and experience its cool features afterwards.