
matinamehdizadeh
Author
In this notebook, we talk about MLOps and walk through a simple example of model deployment.
MLOps, also known as Machine Learning Operations for Production, is a set of standardized practices that can be utilized to build, deploy, and govern the lifecycle of ML models. This setup helps to ease the interaction among cross-functional teams and provides an automated platform to keep track of everything required for the complete cycle of ML models. MLOps practices also result in increased scalability, security, and reliability of the ML systems, leading to shorter development cycles and escalated profits from the ML projects.

MLOps lifecycle has seven different stages. All the processes happen iteratively, and the success of the entire machine learning system comes with the successful execution of each of these stages.
The machine learning lifecycle is the process of developing, deploying, and managing a machine learning model for a specific application. The lifecycle typically consists of:
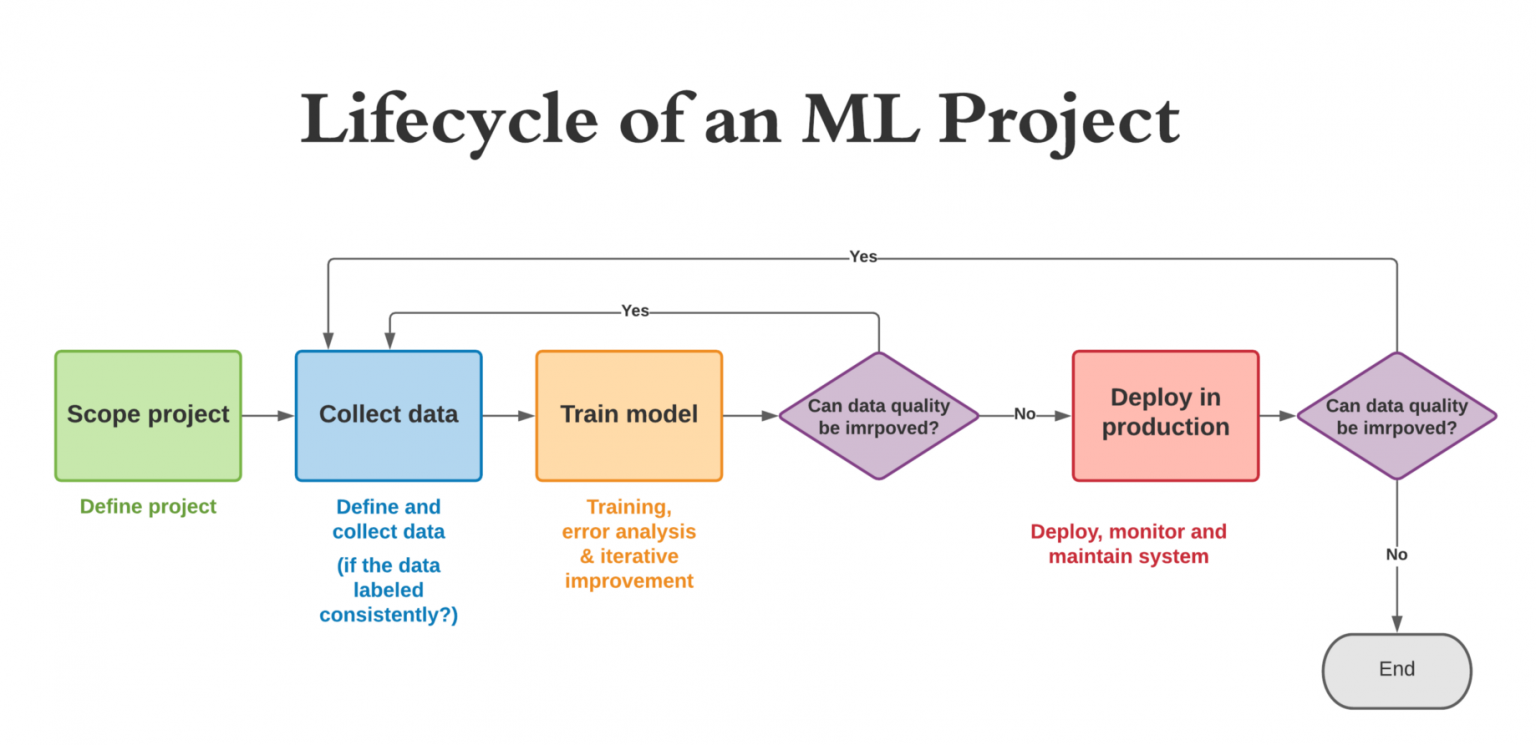
ML Development: This is the basic step that involves creating a complete pipeline beginning from data processing to model training and evaluation codes.
Model Training: Once the setup is ready, the next logical step is to train the model. Here, continuous training functionality is also needed to adapt to new data or address specific changes.
Model Evaluation: Performing inference over the trained model and checking the accuracy/correctness of the output results.
Model Deployment: When the proof of concept stage is accomplished, the other part is to deploy the model according to the industry requirements to face the real-life data.
Prediction Serving: After deployment, the model is now ready to serve predictions over the incoming data.
Model Monitoring: Over time, problems such as concept drift can make the results inaccurate hence continuous monitoring of the model is essential to ensure proper functioning.
Data and Model Management: It is a part of the central system that manages the data and models. It includes maintaining storage, keeping track of different versions, ease of accessibility, security, and configuration across various cross-functional teams.
Models are deployed across the organization and in various systems without a consistent way to monitor them. Models have been in production for a long time and never refreshed.
One of the challenges in ML lifecycle management is manual labor. Every step and the transition between steps are manual. It means data scientists need to collect, analyze, and process data for each application manually. They need to examine their older models to develop new ones and manually fine-tune each time. A large amount of time is allocated to model monitoring to prevent performance degradation. A successful deployment of machine learning models at scale requires automation of steps of the lifecycle. Automation decreases the time allocated to resource-consuming steps such as feature engineering, model training, monitoring, and retraining. It frees up time to rapidly experiment with new models.
The MLOps tools help organizations apply DevOps practices to the process of creating and using AI and machine learning models. These tools are typically used by machine learning engineers, data scientists, and DevOps engineers. MLOps tools can be divided into three major areas.

MLOps Tools for data management consist of data labeling tools which are used to label large volumes of data such as texts, images, or audios and data versioning tools which enable managing different versions of datasets and storing them in an accessible and well-organized way.
MLOps Tools for modeling consist of feature engineering tools that automate the process of extracting useful features from raw datasets to create better training data for machine learning models like Feast. Another tool is for experiment tracking which save all the necessary information about different experiments like MLFlow and the last tool is for Hyperparameter Optimization that automate the process of searching and selecting hyperparameters that give optimal performance for machine learning models.
MLOps Tools for operationalization consist of model deployment tools which facilitate integrating ML models into a production environment to make predictions like Kubeflow. the other tool concerning operationalization is for model monitoring which detect data drifts and anomalies over time and allow setting up alerts in case of performance issues.
In this section we see an example of ml lifrcycle using MLFlow. MLflow is an open source platform for managing the end-to-end machine learning lifecycle. It is designed to work with any machine learning library, determine most things about your code by convention, and require minimal changes to integrate into an existing codebase. First, we install and import nessecary packages.
Next, we define our metric for evaluation.
In the next cell, we first read the wine-quality csv file from the URL and then split the data into training and test sets. Then, we split the target from our data set which is the quality column and at the end we register our model.
The mlflow.start_run function start a new MLflow run, setting it as the active run under which metrics and parameters will be logged, mlflow.log_metric function logs a single key-value metric, mlflow.log_param function logs a single key-value param in the currently active run, mlflow.log_artifact function logs a local file or directory as an artifact and mlflow.set_tracking_uri function set tracking store URI.
%%writefile train.py
# !pip install mlflow
import os
import warnings
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
from urllib.parse import urlparse
import mlflow
import mlflow.sklearn
import logging
logging.basicConfig(level=logging.WARN)
logger = logging.getLogger(__name__)
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
warnings.filterwarnings("ignore")
np.random.seed(40)
csv_url = ("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")
try:
data = pd.read_csv(csv_url, sep=";")
except Exception as e:
logger.exception("Unable to download training & test CSV, check your internet connection. Error: %s", e)
train, test = train_test_split(data)
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
alpha = float(sys.argv[1]) if len(sys.argv) > 1 else 0.5
l1_ratio = float(sys.argv[2]) if len(sys.argv) > 2 else 0.5
with mlflow.start_run():
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
tracking_url_type_store = urlparse(mlflow.get_tracking_uri()).scheme
if tracking_url_type_store != "file":
mlflow.sklearn.log_model(lr, "model", registered_model_name="ElasticnetWineModel")
else:
mlflow.sklearn.log_model(lr, "model")
Overwriting train.py
!python train.py 0.6 0.8
Elasticnet model (alpha=0.600000, l1_ratio=0.800000): RMSE: 0.8326325509502465 MAE: 0.6676500690618903 R2: 0.0177082428508879
!mlflow ui
Then, we serve our model which is to host machine-learning models (on the cloud or on premises) and to make their functions available via API so that applications can incorporate AI into their systems. Model serving is crucial, as a business cannot offer AI products to a large user base without making its product accessible.
!mlflow models serve -m "/Users/model" --no-conda -p 1234
!curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["alcohol", "chlorides", "citric acid", "density", "fixed acidity", "free sulfur dioxide", "pH", "residual sugar", "sulphates", "total sulfur dioxide", "volatile acidity"],"data":[[12.8, 0.029, 0.48, 0.98, 6.2, 29, 3.33, 1.2, 0.39, 75, 0.66]]}' http://127.0.0.1:1234/invocations
The next step is to deploy our model using ducker. First we build the image and then deploy it to our cluster. One way to do this is by applying the respective Kubernetes manifests through the kubectl CLI
!mlflow models build-docker \
-m ./mlruns/0/d1a8010b10f84f5a9b0a51e2b420efb2/artifacts/model \
-n my-docker-image \
--enable-mlserver
!kubectl apply -f my-config.yaml
%%writefile my-manifest.yaml
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: mlflow-model
spec:
predictor:
containers:
- name: mlflow-model
image: my-docker-image
ports:
- containerPort: 8080
protocol: TCP
env:
- name: PROTOCOL
value: v2
MLOps solution provides data scientists with an easier and efficient way to maintain monitor models. By getting models into production and bridging the gap between the stakeholder teams, they can focus on data science. With the help of MLOps, deployment can be done on any platform.
In this nootboke we talk about MLOps and its lifecycle and the nessecity of using it. and at the end we saw an simple example of developing and deploying a model using MLFlow which is a library used for MLOps in python.