
Ali J. Alaee
Author
In this notebook, we study machine learning methods such as online learning, semi-supervised learning, few-shot learning, and meta-learning.
In this notebook, we take a brief look at different Machine Learning methods such as online learning, semi-supervised learning, and few-shot learning. The ultimate goal of this content is to provide a shallow knowledge of the aforementioned topics and helpful resources for further studies.
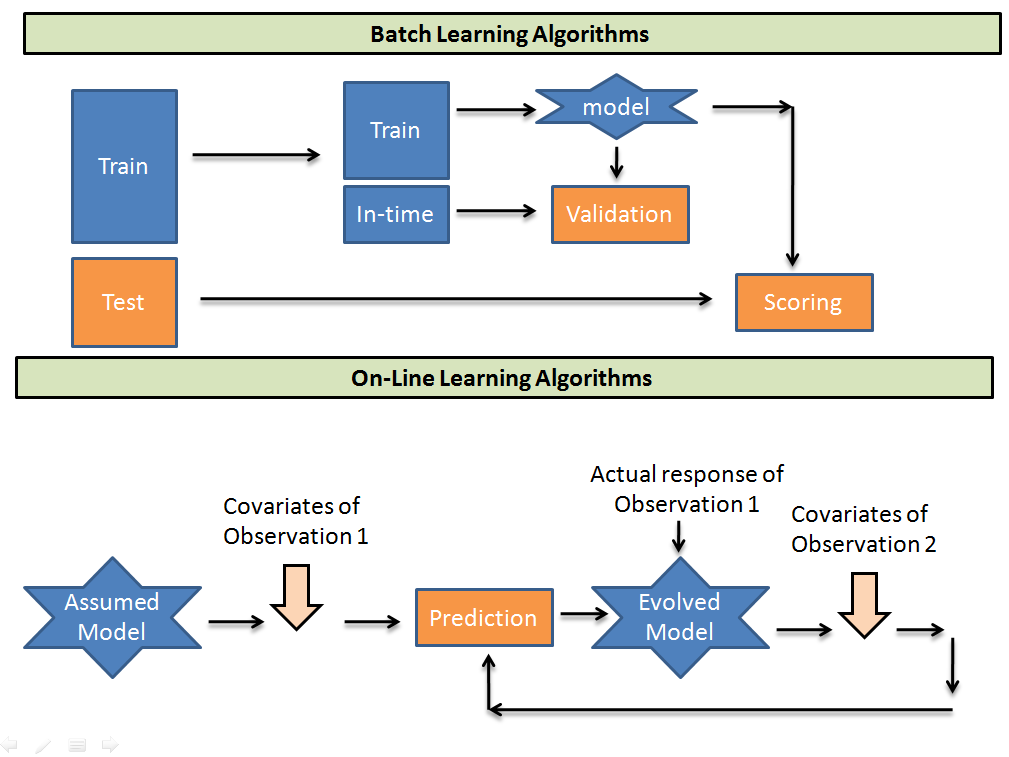
Online machine learning is a machine learning method in which data becomes available in sequential order and is used to update the best predictor for future data at each step, as opposed to batch learning techniques that generate the best predictor by learning on the entire training data set at once. Here is a youtube tutorial that might help with getting more familiar with this group of ML methods.
Continual learning means constantly improving the learned model by processing continuous streams of information. Continual learning capabilities are essential for software systems and autonomous agents interacting in an ever changing real world.
Many refer to continual learning and online learning as synonyms, but people have different opinions on this. Some believe that continual learning is a subset of online learning that deals with catastrophic forgetting, whereas standard “online learning” is more naive and incurs forgetting.
Ideally, what you want is a model that can learn from new examples in something close to real time. Not only predict in real time, but learn in real time, too.
This article provides great information and examples in this regard.
Semi-supervised learning is an approach to machine learning that combines a small amount of labeled data with many unlabeled data during training. Semi-supervised learning falls between unsupervised learning (with no labeled training data) and supervised learning (with only labeled training data). More specifically, it is a particular instance of weak supervision.

Few-shot learning is the problem of making predictions based on a limited number of samples. Few-shot learning is different from standard supervised learning. The general model should adapt efficiently with a small number of training data for a given task. In most cases, we need to prepare a model capable of this fast adaptation.
Support Set: Support set is meta learning’s jargon. The small set of labeled data (e.g., images) is called a support set. Note the differences between the training set and the support set. The training set is extensive. Every class in the training set has many samples. The training set is big enough for the learning process of a deep neural network. In contrast, the support set is small. Every class has at most a few samples. If every class has only one sample in the training set, it is impossible to train a deep neural network. Thus, we have support sets instead of training sets in few-shot learning.
Query Set: Is the set of unlabled data that the model should predict after trained on the support set of this particular task. The definition is close to the test set in regular machine learning methods.
One-Shot Learning: As the title explains, the task only contains one training example to learn.
FSL in Classification: When talking about FSL in classification, we usually mean N-way-K-Shot-classification. N stands for the number of classes, and K for the number of samples from each class to train on.

Few-shot learning is a kind of meta-learning. Meta-learning is different from traditional supervised learning. Conventional supervised learning asks the model to recognize the training data and then generalize to unseen test data. Differently, meta learning’s goal is to learn. In other words, in meta-learning, the goal is to find a set of parameters that can adapt as quickly as possible for a new given task. We discuss one of the essential meta-learning platforms in the following section.
MAML, or Model-Agnostic Meta-Learning, is a model and task-agnostic algorithm for meta-learning that trains a model’s parameters such that a small number of gradient updates will lead to fast learning on a new task.
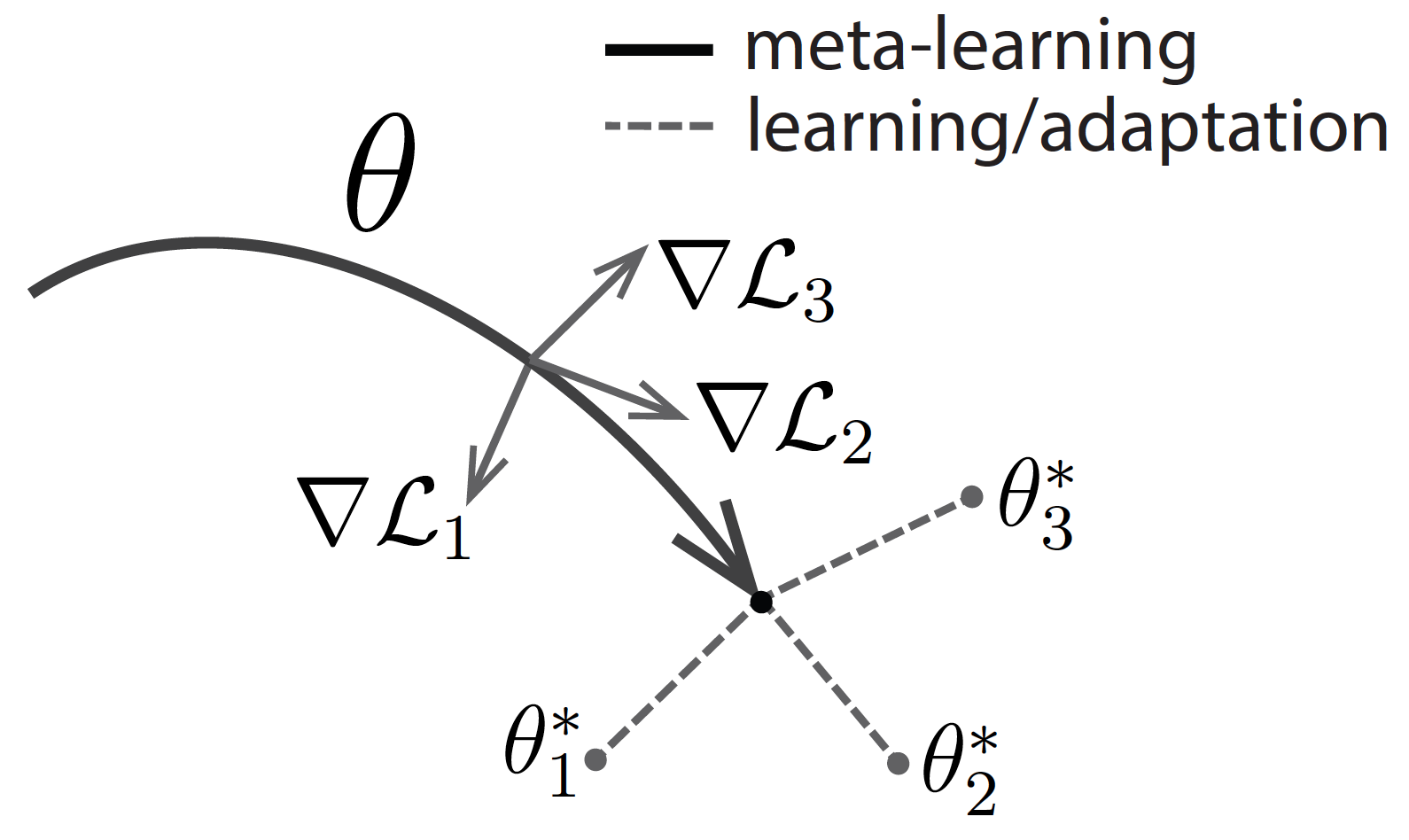
In this algorithm, which can be used in federated learning, each agent adapts the general set of parameters (known as theta) independently for its task using the support set. Subsequently, the gradient of the loss function using the query set (which is also labeled because it is in the learning section) is computed and transferred to the root. Then, the root updates the general theta concerning all the received gradients of different agents (tasks).
Here is the link to the original paper proposing MAML.
MAML is easily implemented on the learn2learn GitHub repository. A simple experiment could be running this python file, which executes MAML for MNIST image classification tasks. You can manage input parameters by providing proper arguments to this python code.
Check these links out for more information on topics covered in this notebook.