
Nima Jamali
Author
In this notebook, we talk about natural language processing, common challenges, and different approaches for working with text.
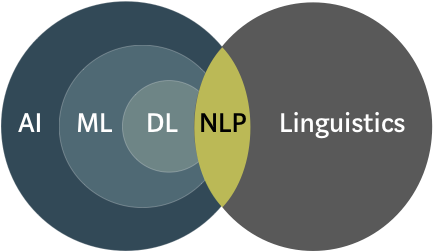
Natural Language Processing (NLP) is a confluence of Artificial Intelligence and Linguistics which tries to enable computers to understand natural language data, including text, speech, etc. Tasks like Speech Recognition, Machine Translation, Text-to-speech and Part-of-speech Tagging are just some of NLP's branches.
Historically, Turing test can be considered as a starting point in the realm of Natural Language Processing. Some single-purpose systems like SHRDLU and PARRY were developed by rule-based methods.
There are two revolutions in NLP, the first one happened in late 1980's with introduction of machine learning which came up with statistical models and caused remarkable successes especially in machine translation. Deep learning methods which were introduced in 2010's outperformed previous methods and thus they are considered as second revoloution in NLP.
Through this notebook, we will study main challenges and problem-solving approaches in NLP and introduce some related libraries in Python.
There are number of challenges and limitations in NLP that we should be aware of. Throughout this section, we will study some of these challenges. Some of these challenges are not completely solved yet.
Same words can have different meanings according the context of the context of a sentence. For example, consider apple which can refer to both the fruit and the company. Or another example is "He can can a can!" which contains same word "can" with three different meanings. Humans can understand the meaning related to the context but differentiating between these meanings for a computer may be challenging.
As another case, consider homophones which are words or phrases sharing same pronounciation while having different meanings, words like "by", "bye" and "buy" and phrases like "some others" and "some mothers". Detecting these homophones are sometimes hard even for people.
One of challenges in NLP is deciding where sentences begin and end. This is mostly because of using punctuation marks which can create ambiguity. As an example, if we simply define full stop as the end of a sentence, then we may face counterexamples as this character may refer to an abbreviation or a decimal number. Rule-based and deep learning approaches are used to solve this problem.
Sometimes group of words can have two or more interpretations. Consider the following statement:
which can means "There was a man on the hill and I saw him using my telescope" while it can be interpreted as "I saw a man on the hill and he had a telescope". These ambiguities are sometimes hard to be cleared up since they should be interpreted according to the context. Part-of-speech tagging is one NLP soloution which can help solving this problem.
Above challenges were just some examples of existing challenges in NLP. Irony and sarcasm, colloquialisms and slang, etc. are some other examples of problems in NLP. For further information you can checkout links provided in Useful Links section.
Regular expressions and context free grammars are famous rule-based methods which can be beneficial for some tasks like parsing. Let's contemplate search queries for plane tickets. A suggested context free grammar for parsing these queries is provided below:

There are some problems with rule-based methods. First, these rules must be generated manually. In addition, the person who defines these rules probably should have high linguistic skills. The other problem is that rule-based methods are not scalable. Imagine how hard it would be if we want to put all cities' names in CITY grammar in above example; however, rule-based methods usually achieve high accuracy if rules are defined precisely.
This is exactly like what you've seen before in other machine learning tasks. So, first we should have a dataset which is usually a corpus. Then we should do some feature engineering to find features related to our desired task. For example Does this word begin with a capital letter? or What words came before and after this word?. Next a model like naive Bayes classifier, random forest or etc. should be trained.
In following cells we will build a sentiment analysis classifier using Python. Throughout these codes, we will introduce Natural Language Toolkit (NLTK) that contains many useful classes and functions related to NLP tasks.
# Loading dataset
import nltk
nltk.download('movie_reviews')
from nltk.corpus import movie_reviews
from random import shuffle
movie_reviews.categories()
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
# Documents are now saved as a tuple: (words list, label)
shuffle(documents)
documents[0]
[nltk_data] Downloading package movie_reviews to /root/nltk_data... [nltk_data] Package movie_reviews is already up-to-date!
(['you', 'know', 'the', 'plot', ':', 'a', 'dimwit', 'with', 'a', 'shady', 'past', 'is', 'seduced', 'into', 'committing', 'a', 'crime', 'only', 'to', 'be', 'double', '-', 'crossed', 'by', 'a', 'fatal', 'femme', '.', 'in', '"', 'palmetto', ',', '"', 'the', 'dimwit', 'is', 'harry', 'barber', '(', 'woody', 'harrelson', ')', ',', 'a', 'reporter', 'who', "'", 's', 'just', 'been', 'released', 'from', 'prison', '(', 'he', 'was', 'framed', 'by', 'the', 'gangsters', 'and', 'corrupt', 'officials', 'he', 'was', 'investigating', ')', '.', 'enter', 'la', 'femme', ':', 'rhea', 'malroux', '(', 'elisabeth', 'shue', ')', ',', 'the', 'sexy', 'young', 'wife', 'of', 'the', 'richest', 'man', 'in', 'palmetto', ',', 'florida', '(', 'rolf', 'hoppe', ')', '.', 'she', 'and', 'her', 'stepdaughter', 'odette', '(', 'chlo', '?', 'sevigny', ')', 'have', 'a', 'plot', 'to', 'extort', '500k', 'from', 'the', 'old', 'man', ':', 'harry', 'will', '"', 'kidnap', '"', 'odette', '.', 'after', 'groping', 'both', 'women', ',', 'harry', 'agrees', '.', 'as', 'everyone', 'except', 'harry', 'can', 'see', ',', 'he', "'", 's', 'being', 'set', 'up', 'as', 'a', 'fall', 'guy', '.', 'sure', 'enough', ',', 'before', 'long', ',', 'harry', 'has', 'a', 'dead', 'body', 'in', 'his', 'trunk', 'and', 'the', 'cops', 'on', 'his', 'tail', '.', 'his', 'brother', '-', 'in', '-', 'law', '(', 'tom', 'wright', ')', ',', 'an', 'assistant', 'da', ',', 'has', 'hired', 'harry', 'to', 'be', 'the', 'press', 'liaison', 'for', 'the', 'case', ',', 'so', 'harry', 'gets', 'a', 'front', 'row', 'seat', 'for', 'his', 'own', 'manhunt', '(', 'and', 'we', 'get', 'to', 'watch', 'him', 'sweat', '-', 'literally', ')', '.', 'there', 'are', 'several', 'plot', 'twists', ',', 'of', 'course', '-', 'a', 'couple', 'of', 'them', 'even', 'took', 'me', 'by', 'surprise', '.', 'apparently', 'every', 'woman', 'in', 'palmetto', 'is', 'a', 'raving', 'horndog', ',', 'and', 'they', "'", 're', 'on', 'harry', 'like', 'he', "'", 's', 'the', 'only', 'bone', 'in', 'the', 'kennel', '.', 'shue', 'vamps', 'so', 'broadly', 'that', 'i', 'expected', 'tex', 'avery', "'", 's', 'wolf', 'to', 'show', 'up', '.', 'her', 'incredible', 'performance', 'in', '"', 'leaving', 'las', 'vegas', '"', 'seems', 'to', 'have', 'been', 'a', 'fluke', '.', 'here', ',', 'she', 'could', 'easily', 'be', 'mistaken', 'for', 'melanie', 'griffith', '.', 'shue', "'", 's', 'character', 'is', 'supposed', 'to', 'be', 'a', 'savvy', 'schemer', 'but', 'she', 'comes', 'off', 'as', 'a', 'brainless', 'bimbo', '.', 'in', 'addition', 'to', 'shue', 'and', 'sevigny', ',', 'the', 'kennel', 'includes', 'gina', 'gershon', '(', 'who', 'filled', 'the', 'dimwit', '-', 'with', '-', 'a', '-', 'shady', '-', 'past', 'role', 'in', '"', 'bound', '"', ')', 'as', 'harry', "'", 's', 'girlfriend', 'nina', ';', 'when', 'harry', 'gets', 'out', 'of', 'jail', ',', 'she', 'licks', 'his', 'face', '(', 'now', 'there', "'", 's', 'a', 'horndog', ')', '.', 'the', 'parts', 'are', 'so', 'overplayed', 'that', 'with', 'a', 'little', 'push', '"', 'palmetto', '"', 'could', 'have', 'been', 'an', 'over', '-', 'the', '-', 'top', 'parody', 'of', 'film', 'noir', 'a', 'la', '"', 'romeo', 'is', 'bleeding', '.', '"', 'as', 'it', 'is', ',', 'it', "'", 's', 'best', 'watched', 'at', '2am', 'on', 'showtime', '(', 'the', 'love', 'scenes', 'seem', 'to', 'have', 'been', 'written', 'for', 'one', 'of', 'that', 'channel', "'", 's', 'soft', 'porn', 'programs', 'anyway', ')', '.', '"', 'palmetto', '"', 'has', 'a', 'well', '-', 'known', 'director', ',', 'volker', 'schl', '?', 'ndorff', ',', 'who', "'", 's', 'best', 'known', 'for', 'his', 'adaptations', 'of', 'major', 'literary', 'works', ',', 'especially', '"', 'the', 'tin', 'drum', '.', '"', 'i', 'suppose', 'he', 'must', 'have', 'been', 'drawn', 'to', 'this', 'plot', '-', 'by', '-', 'numbers', 'script', 'by', 'the', 'same', 'admiration', 'for', 'classic', 'film', 'noir', 'that', 'led', 'scorsese', 'to', 'remake', '"', 'cape', 'fear', '.', '"', 'schl', '?', 'ndorff', 'tries', 'hard', '-', 'he', 'makes', 'an', 'interesting', 'motif', 'out', 'of', 'the', 'ubiquitous', 'palmetto', 'bugs', '-', 'but', 'nothing', 'can', 'freshen', 'up', 'this', 'stale', 'script', '.'], 'neg')
# Selecting 5000 words from whole to be word features (removing punctuations and stopwords)
nltk.download("stopwords")
stopwords = nltk.corpus.stopwords.words("english")
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words() if w.isalpha() and not w.lower() in stopwords)
word_features = list(all_words)[:3000]
word_features
[nltk_data] Downloading package stopwords to /root/nltk_data... [nltk_data] Package stopwords is already up-to-date!
['plot', 'two', 'teen', 'couples', 'go', 'church', 'party', 'drink', 'drive', 'get', 'accident', 'one', 'guys', 'dies', 'girlfriend', 'continues', 'see', 'life', 'nightmares', 'deal', 'watch', 'movie', 'sorta', 'find', 'critique', 'mind', 'fuck', 'generation', 'touches', 'cool', 'idea', 'presents', 'bad', 'package', 'makes', 'review', 'even', 'harder', 'write', 'since', 'generally', 'applaud', 'films', 'attempt', 'break', 'mold', 'mess', 'head', 'lost', 'highway', 'memento', 'good', 'ways', 'making', 'types', 'folks', 'snag', 'correctly', 'seem', 'taken', 'pretty', 'neat', 'concept', 'executed', 'terribly', 'problems', 'well', 'main', 'problem', 'simply', 'jumbled', 'starts', 'normal', 'downshifts', 'fantasy', 'world', 'audience', 'member', 'going', 'dreams', 'characters', 'coming', 'back', 'dead', 'others', 'look', 'like', 'strange', 'apparitions', 'disappearances', 'looooot', 'chase', 'scenes', 'tons', 'weird', 'things', 'happen', 'explained', 'personally', 'trying', 'unravel', 'film', 'every', 'give', 'clue', 'kind', 'fed', 'biggest', 'obviously', 'got', 'big', 'secret', 'hide', 'seems', 'want', 'completely', 'final', 'five', 'minutes', 'make', 'entertaining', 'thrilling', 'engaging', 'meantime', 'really', 'sad', 'part', 'arrow', 'dig', 'flicks', 'actually', 'figured', 'half', 'way', 'point', 'strangeness', 'start', 'little', 'bit', 'sense', 'still', 'guess', 'bottom', 'line', 'movies', 'always', 'sure', 'given', 'password', 'enter', 'understanding', 'mean', 'showing', 'melissa', 'sagemiller', 'running', 'away', 'visions', 'throughout', 'plain', 'lazy', 'okay', 'people', 'chasing', 'know', 'need', 'giving', 'us', 'different', 'offering', 'insight', 'apparently', 'studio', 'took', 'director', 'chopped', 'shows', 'might', 'decent', 'somewhere', 'suits', 'decided', 'turning', 'music', 'video', 'edge', 'would', 'actors', 'although', 'wes', 'bentley', 'seemed', 'playing', 'exact', 'character', 'american', 'beauty', 'new', 'neighborhood', 'kudos', 'holds', 'entire', 'feeling', 'unraveling', 'overall', 'stick', 'entertain', 'confusing', 'rarely', 'excites', 'feels', 'redundant', 'runtime', 'despite', 'ending', 'explanation', 'craziness', 'came', 'oh', 'horror', 'slasher', 'flick', 'packaged', 'someone', 'assuming', 'genre', 'hot', 'kids', 'also', 'wrapped', 'production', 'years', 'ago', 'sitting', 'shelves', 'ever', 'whatever', 'skip', 'joblo', 'nightmare', 'elm', 'street', 'blair', 'witch', 'crow', 'salvation', 'stir', 'echoes', 'happy', 'bastard', 'quick', 'damn', 'bug', 'starring', 'jamie', 'lee', 'curtis', 'another', 'baldwin', 'brother', 'william', 'time', 'story', 'regarding', 'crew', 'tugboat', 'comes', 'across', 'deserted', 'russian', 'tech', 'ship', 'kick', 'power', 'within', 'gore', 'bringing', 'action', 'sequences', 'virus', 'empty', 'flash', 'substance', 'middle', 'nowhere', 'origin', 'pink', 'flashy', 'thing', 'hit', 'mir', 'course', 'donald', 'sutherland', 'stumbling', 'around', 'drunkenly', 'hey', 'let', 'robots', 'acting', 'average', 'likes', 'likely', 'work', 'halloween', 'wasted', 'real', 'star', 'stan', 'winston', 'robot', 'design', 'schnazzy', 'cgi', 'occasional', 'shot', 'picking', 'brain', 'body', 'parts', 'turn', 'otherwise', 'much', 'sunken', 'jaded', 'viewer', 'thankful', 'invention', 'timex', 'indiglo', 'based', 'late', 'television', 'show', 'name', 'mod', 'squad', 'tells', 'tale', 'three', 'reformed', 'criminals', 'employ', 'police', 'undercover', 'however', 'wrong', 'evidence', 'gets', 'stolen', 'immediately', 'suspicion', 'ads', 'cuts', 'claire', 'dane', 'nice', 'hair', 'cute', 'outfits', 'car', 'chases', 'stuff', 'blowing', 'sounds', 'first', 'fifteen', 'quickly', 'becomes', 'apparent', 'certainly', 'slick', 'looking', 'complete', 'costumes', 'enough', 'best', 'described', 'cross', 'hour', 'long', 'cop', 'stretched', 'span', 'single', 'clich', 'matter', 'elements', 'recycled', 'everything', 'already', 'seen', 'nothing', 'spectacular', 'sometimes', 'bordering', 'wooden', 'danes', 'omar', 'epps', 'deliver', 'lines', 'bored', 'transfers', 'onto', 'escape', 'relatively', 'unscathed', 'giovanni', 'ribisi', 'plays', 'resident', 'crazy', 'man', 'ultimately', 'worth', 'watching', 'unfortunately', 'save', 'convoluted', 'apart', 'occupying', 'screen', 'young', 'cast', 'clothes', 'hip', 'soundtrack', 'appears', 'geared', 'towards', 'teenage', 'mindset', 'r', 'rating', 'content', 'justify', 'juvenile', 'older', 'information', 'literally', 'spoon', 'hard', 'instead', 'telling', 'dialogue', 'poorly', 'written', 'extremely', 'predictable', 'progresses', 'care', 'heroes', 'jeopardy', 'basing', 'nobody', 'remembers', 'questionable', 'wisdom', 'especially', 'considers', 'target', 'fact', 'number', 'memorable', 'counted', 'hand', 'missing', 'finger', 'times', 'checked', 'six', 'clear', 'indication', 'cash', 'spending', 'dollar', 'judging', 'rash', 'awful', 'seeing', 'avoid', 'costs', 'quest', 'camelot', 'warner', 'bros', 'feature', 'length', 'fully', 'animated', 'steal', 'clout', 'disney', 'cartoon', 'empire', 'mouse', 'reason', 'worried', 'recent', 'challenger', 'throne', 'last', 'fall', 'promising', 'flawed', 'century', 'fox', 'anastasia', 'hercules', 'lively', 'colorful', 'palate', 'beat', 'hands', 'crown', 'piece', 'animation', 'year', 'contest', 'arrival', 'magic', 'kingdom', 'mediocre', 'pocahontas', 'keeping', 'score', 'nearly', 'dull', 'revolves', 'adventures', 'free', 'spirited', 'kayley', 'voiced', 'jessalyn', 'gilsig', 'early', 'daughter', 'belated', 'knight', 'king', 'arthur', 'round', 'table', 'dream', 'follow', 'father', 'footsteps', 'chance', 'evil', 'warlord', 'ruber', 'gary', 'oldman', 'ex', 'gone', 'steals', 'magical', 'sword', 'excalibur', 'accidentally', 'loses', 'dangerous', 'booby', 'trapped', 'forest', 'help', 'hunky', 'blind', 'timberland', 'dweller', 'garrett', 'carey', 'elwes', 'headed', 'dragon', 'eric', 'idle', 'rickles', 'arguing', 'able', 'medieval', 'sexist', 'prove', 'fighter', 'side', 'pure', 'showmanship', 'essential', 'element', 'expected', 'climb', 'high', 'ranks', 'differentiates', 'something', 'saturday', 'morning', 'subpar', 'instantly', 'forgettable', 'songs', 'integrated', 'computerized', 'footage', 'compare', 'run', 'angry', 'ogre', 'herc', 'battle', 'hydra', 'rest', 'case', 'stink', 'none', 'remotely', 'interesting', 'race', 'bland', 'end', 'tie', 'win', 'comedy', 'shtick', 'awfully', 'cloying', 'least', 'signs', 'pulse', 'fans', 'tgif', 'thrilled', 'jaleel', 'urkel', 'white', 'bronson', 'balki', 'pinchot', 'sharing', 'nicely', 'realized', 'though', 'loss', 'recall', 'specific', 'providing', 'voice', 'talent', 'enthusiastic', 'paired', 'singers', 'sound', 'musical', 'moments', 'jane', 'seymour', 'celine', 'dion', 'must', 'strain', 'aside', 'children', 'probably', 'adults', 'grievous', 'error', 'lack', 'personality', 'learn', 'goes', 'synopsis', 'mentally', 'unstable', 'undergoing', 'psychotherapy', 'saves', 'boy', 'potentially', 'fatal', 'falls', 'love', 'mother', 'fledgling', 'restauranteur', 'unsuccessfully', 'attempting', 'gain', 'woman', 'favor', 'takes', 'pictures', 'kills', 'comments', 'stalked', 'yet', 'seemingly', 'endless', 'string', 'spurned', 'psychos', 'getting', 'revenge', 'type', 'stable', 'category', 'industry', 'theatrical', 'direct', 'proliferation', 'may', 'due', 'typically', 'inexpensive', 'produce', 'special', 'effects', 'stars', 'serve', 'vehicles', 'nudity', 'allowing', 'frequent', 'night', 'cable', 'wavers', 'slightly', 'norm', 'respect', 'psycho', 'never', 'affair', 'contrary', 'rejected', 'rather', 'lover', 'wife', 'husband', 'entry', 'doomed', 'collect', 'dust', 'viewed', 'midnight', 'provide', 'suspense', 'sets', 'interspersed', 'opening', 'credits', 'instance', 'serious', 'sounding', 'narrator', 'spouts', 'statistics', 'stalkers', 'ponders', 'cause', 'stalk', 'implicitly', 'implied', 'men', 'shown', 'snapshot', 'actor', 'jay', 'underwood', 'states', 'daryl', 'gleason', 'stalker', 'brooke', 'daniels', 'meant', 'called', 'guesswork', 'required', 'proceeds', 'begins', 'obvious', 'sequence', 'contrived', 'quite', 'brings', 'victim', 'together', 'obsesses', 'follows', 'tries', 'woo', 'plans', 'become', 'desperate', 'elaborate', 'include', 'cliche', 'murdered', 'pet', 'require', 'found', 'exception', 'cat', 'shower', 'events', 'lead', 'inevitable', 'showdown', 'survives', 'invariably', 'conclusion', 'turkey', 'uniformly', 'adequate', 'anything', 'home', 'either', 'turns', 'toward', 'melodrama', 'overdoes', 'words', 'manages', 'creepy', 'pass', 'demands', 'maryam', 'abo', 'close', 'played', 'bond', 'chick', 'living', 'daylights', 'equally', 'title', 'ditzy', 'strong', 'independent', 'business', 'owner', 'needs', 'proceed', 'example', 'suspicions', 'ensure', 'use', 'excuse', 'decides', 'return', 'toolbox', 'left', 'place', 'house', 'leave', 'door', 'answers', 'opens', 'wanders', 'returns', 'enters', 'heroine', 'danger', 'somehow', 'parked', 'front', 'right', 'oblivious', 'presence', 'inside', 'whole', 'episode', 'places', 'incredible', 'suspension', 'disbelief', 'questions', 'validity', 'intelligence', 'receives', 'highly', 'derivative', 'somewhat', 'boring', 'cannot', 'watched', 'rated', 'mostly', 'several', 'murder', 'brief', 'strip', 'bar', 'offensive', 'many', 'thrillers', 'mood', 'stake', 'else', 'capsule', 'planet', 'mars', 'taking', 'custody', 'accused', 'murderer', 'face', 'menace', 'lot', 'fighting', 'john', 'carpenter', 'reprises', 'ideas', 'previous', 'assault', 'precinct', 'homage', 'believes', 'fight', 'horrible', 'writer', 'supposedly', 'expert', 'mistake', 'ghosts', 'drawn', 'humans', 'surprisingly', 'low', 'powered', 'alien', 'addition', 'anybody', 'made', 'grounds', 'sue', 'chock', 'full', 'pieces', 'prince', 'darkness', 'surprising', 'managed', 'fit', 'admittedly', 'novel', 'science', 'fiction', 'experience', 'terraformed', 'walk', 'surface', 'without', 'breathing', 'gear', 'budget', 'mentioned', 'gravity', 'increased', 'earth', 'easier', 'society', 'changed', 'advanced', 'culture', 'women', 'positions', 'control', 'view', 'stagnated', 'female', 'beyond', 'minor', 'technological', 'advances', 'less', 'expect', 'change', 'ten', 'basic', 'common', 'except', 'yes', 'replaced', 'tacky', 'rundown', 'martian', 'mining', 'colony', 'criminal', 'napolean', 'wilson', 'desolation', 'williams', 'facing', 'hoodlums', 'automatic', ...]
# We simply define 3000 word features indicating whether document contains that word or not
def extract_features(document):
document_words = set(document)
features = {}
for word in word_features:
features[f'contains ({word})'] = (word in document_words)
return features
# Using naive Bayes classifier
final_dataset = [(extract_features(d), c) for (d,c) in documents]
train_set, test_set = final_dataset[:int(0.9 * len(documents))], final_dataset[int(0.9 * len(documents)):]
classifier = nltk.NaiveBayesClassifier.train(train_set)
nltk.classify.accuracy(classifier, test_set)
0.84
As you see, we achieved accuracy of 84% using simple features and without any parameter tuning! Now let's see which words are most informative features.
classifier.show_most_informative_features(10)
Most Informative Features
contains (sucks) = True neg : pos = 10.0 : 1.0
contains (unimaginative) = True neg : pos = 8.5 : 1.0
contains (annual) = True pos : neg = 8.2 : 1.0
contains (frances) = True pos : neg = 7.5 : 1.0
contains (silverstone) = True neg : pos = 7.1 : 1.0
contains (schumacher) = True neg : pos = 7.1 : 1.0
contains (atrocious) = True neg : pos = 6.7 : 1.0
contains (chambers) = True neg : pos = 6.4 : 1.0
contains (crappy) = True neg : pos = 6.4 : 1.0
contains (turkey) = True neg : pos = 6.4 : 1.0
Neural networks architectures are now widely used in different NLP tasks. Recurrent Neural Networks (RNNs) are able to process sequential information. Many-to-one RNNs can be used for text classification problems, one-to-many RNNs are good for text generation tasks and many-to-many RNNs are useful in machine translation.
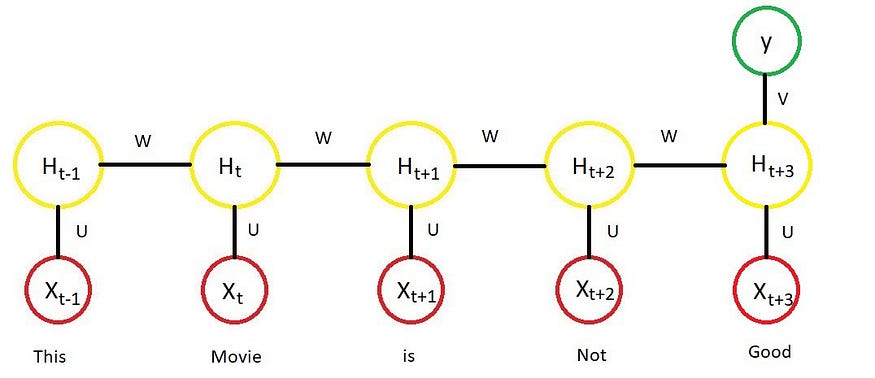
Other approaches like Long Short-term Memory (LSTM), Attention Mechanism and Deep Generative Models are used in different NLP tasks.
Now it's time to see how deep models can be useful in representing words. In NLP tasks we usually need to show words numerically, e.g., using vectors. TF-IDF approach -which doesn't use neural networks- can show significance of each word in the document using its frequency in the given document and whole corpus. But it doesn't capture similarities between words. Furthermore, vectors are high dimensional since every word is a feature.
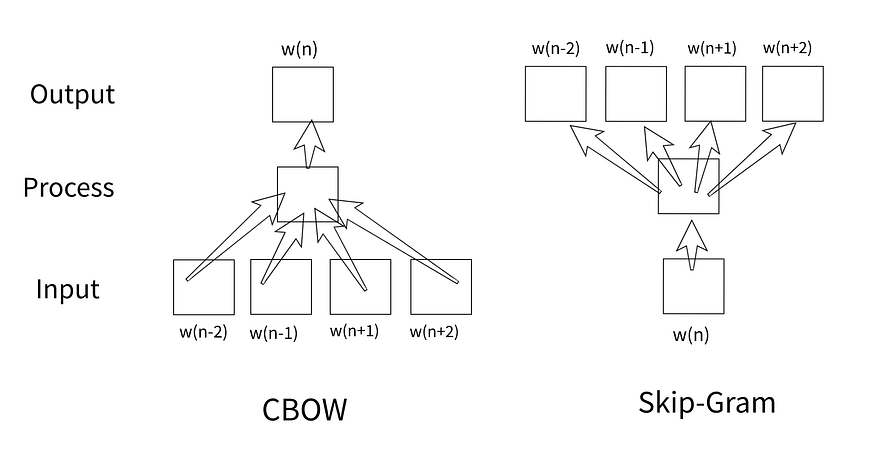
Word2Vec is an alternative approach which uses neural networks to find word embeddings. It can discover similarities between words such that words which are semantically close together have similar embeddings. Vector size is much less than vocabulary size and is usually selected according to corpus size.
Two famous Word2Vec architectures are continuous bag-of-words (CBOW) and skip-gram. CBOW uses surrounding words to predict current word while skip-gram aims to predict surrounding words using current word.
In following cell we will try to create a Word2Vec model using movie_reviews dataset which was imported in last section.
from gensim.models import Word2Vec
documents_words = [doc[0] for doc in documents]
model = Word2Vec(sentences=documents_words, size=100, window=5, min_count=1, workers=4)
Now let's see which words are mostly similar to the word ship using Word2Vec.
sims = model.wv.most_similar('ship', topn=10) # get other similar words
sims
[('island', 0.9006446003913879), ('plane', 0.8913903832435608), ('country', 0.886518120765686), ('land', 0.8806939125061035), ('room', 0.8713586926460266), ('planet', 0.8674205541610718), ('floor', 0.8587629199028015), ('government', 0.856345534324646), ('boat', 0.8548795580863953), ('fire', 0.8527746200561523)]
Interesting! As we expected, we see words which are semantically close to the word ship, such as island, boat, plane, room, etc.
You can test other words using same syntax.
